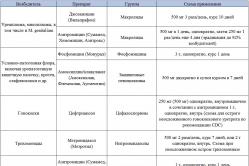
Antipyretika für Kinder werden von einem Kinderarzt verschrieben. Aber es gibt Notfallsituationen für Fieber, wenn das Kind sofort Medikamente erhalten muss. Dann übernehmen die Eltern die Verantwortung und nehmen fiebersenkende Medikamente. Was darf Säuglingen gegeben werden? Wie kann man bei älteren Kindern die Temperatur senken? Welche Medikamente sind am sichersten?
Grundlegendes Konzept
Algorithmus - Dies ist eine Vorschrift (eine Ordnung oder ein System von Ordnungen), die den Prozess der Umwandlung der Ausgangsdaten in das gewünschte Ergebnis k bestimmt, das die folgenden Eigenschaften hat:
- Gewissheit, d. h. Genauigkeit und Verständlichkeit für Führungskräfte; Aufgrund dieser Eigenschaft ist der Prozess der Ausführung des Algorithmus mechanisch;
- Effektivität, d. h. die Fähigkeit, nach endlich vielen recht einfachen Schritten zum gewünschten Ergebnis zu führen;
- Massencharakter, d.h. Eignung zur Lösung beliebiger Probleme aus einer bestimmten Klasse von Problemen.
Aus der Definition des Algorithmus ist ersichtlich, dass der Prozess seiner Implementierung diskret sein muss, bestehend aus separaten Schritten, algorithmischen Handlungen. Die Forderung nach Einfachheit dieser Schritte rührt daher, dass wir unter der Annahme einer unbegrenzten Komplexität der Schritte dem Konzept eines Algorithmus jede Gewissheit nehmen. Die Eigenschaft eines Algorithmus, in endlich vielen Schritten zu einer Lösung zu führen, wird als potentielle Machbarkeit bezeichnet.
Natürliche Sprachen nützen wenig, um in ihnen eindeutige und präzise Vorschriften zu formulieren. Der Algorithmus muss daher ein Rezept in einer formalen Sprache sein.
Jeder Computer ist darauf ausgelegt, hauptsächlich Probleme einer bestimmten Klasse zu lösen. In dieser Hinsicht ist es erforderlich, dass der Computer die Fähigkeit bereitstellt, die erforderlichen Kombinationen eines bestimmten Satzes von Operationen auszuführen, die als elementar betrachtet werden.
Elementare Maschinenoperationen sind die Eingabe von Informationen in eine Zelle eines Direktzugriffsspeichers von einem anderen Speichergerät, die Ausgabe von Informationen aus der Zelle sowie jede Operation, die: in Hardware implementiert ist; hat Anfangsdaten, die das Ergebnis elementarer Maschinenoperationen sind und in einer oder mehreren Zellen fixiert sind; liefert ein Ergebnis, das in einer separaten Zelle fixiert ist und verfügbar ist, aber nicht obligatorisch für die Verwendung als Anfangsdaten einer elementaren Operation der Maschine; kann nicht als Komplex einfacherer Maschinenoperationen betrachtet werden, die die drei vorherigen Bedingungen erfüllen.
Betriebssystem ist die Gesamtheit aller im Computer bereitgestellten Maschinenoperationen.
Befehl ist eine elementare Vorschrift, die die Durchführung einer bestimmten Gruppe von Operationen vorsieht.
Hauptoperationen Computer sind arithmetische, logische, Übertragungen, Übergänge, wenn die Maschine einen Übergang von der Ausführung eines Befehls zur Ausführung eines anderen durchführt, Befehle aus dem RAM abruft und die Maschine anhält („Stopp“). Die Hauptoperationen an wörtlichen Informationen sind: Bestimmen der Länge eines Wortes; Übertragung eines Wortes von einer Stelle des RAM zu einer anderen; Hervorheben eines bestimmten Teils eines bestimmten Wortes; Einbeziehung von Leerzeichen zwischen Wörtern; Aufteilen einer Wortfolge in kleinere Folgen; Vergleich zweier Wörter. Normalerweise werden diese Vorgänge als Editieren bezeichnet.
Programmierung
Computer werden normalerweise entweder zur Lösung einzelner Probleme (die zu einer bestimmten Klasse gehören) oder zur Lösung eines Komplexes zusammenhängender Probleme verschiedener Klassen verwendet.
Beim Lösen einer bestimmten Aufgabe (Klasse von Aufgaben) auf einem Computer wird die Arbeit in die folgenden Phasen unterteilt:
mathematische Formulierung des Problems;
Entwicklung einer Methodik zu ihrer Lösung;
Entwicklung eines Algorithmus zur Lösung und Schreiben in einer Programmiersprache;
Programmierung;
Debuggen des Programms auf der Maschine;
Vorbereitung der Ausgangsdaten, Lösung des Problems auf einem Computer.
Der beschriebene Werkkomplex heißt Problemprogrammierung.
Bei der Entwicklung eines Programmsystems zur Lösung eines Komplexes zusammenhängender Aufgaben bleibt während der Entwicklung jedes Programms der beschriebene Arbeitsablauf erhalten. Darüber hinaus gibt es eine Reihe zusätzlicher Arbeitsschritte, die mit der Notwendigkeit verbunden sind, die Einheit des Systems sicherzustellen. Eine Reihe von Arbeiten zur Erstellung eines Programmsystems zur Lösung zusammenhängender Aufgaben wird aufgerufen Systemprogrammierung.
Mathematische Formulierung des Problems. Diese Arbeit besteht darin, die Zusammensetzung und Art der Ausgangsdaten zur Lösung des Problems zu bestimmen, die Ausgangsergebnisse zu bestimmen und die Bedingungen des Problems in mathematischer Notation zu schreiben. Der mathematische Apparat, der bei der mathematischen Formulierung des Problems verwendet wird, hängt davon ab, zu welcher Klasse das Problem gehört.
Entwicklung einer Problemlösungstechnik. Eine Lösungstechnik gilt als entwickelt, wenn die Abhängigkeiten aller gewünschten Ergebnisse von den Ausgangsergebnissen festgestellt sind und solche Verfahren zum Erhalten der gewünschten Ergebnisse angegeben sind, die auf einem Computer implementiert werden können. Wenn die Ungeeignetheit der gewählten Methoden bei der Lösung des Problems auf einem Computer festgestellt wird, ist es notwendig, zur Phase der Methodenentwicklung zurückzukehren.
Entwicklung eines Algorithmus zur Lösung des Problems. Auf der Grundlage der Methodik zur Lösung wird ein Algorithmus zur Lösung des Problems entwickelt. Der Algorithmus wird in der Sprache mathematischer Beschreibungen entwickelt und dann in einer algorithmischen Sprache aus den sogenannten Programmiersprachen geschrieben. Die Entwicklung eines Algorithmus zur Lösung des Problems sollte unter Berücksichtigung der Eigenschaften des Computers erfolgen.
Bei der Verwendung eines Computers zur Lösung eines Problems müssen die folgenden Merkmale berücksichtigt werden:
- eine große, aber begrenzte Anzahl von Ziffern in Zahlenbildern;
- höhere Geschwindigkeit bei der Ausführung von Operationen mit im RAM gespeicherten Zahlen;
- relativ langsame Eingabe von Anfangsdaten und Ausgabe von Ergebnissen;
- relativ niedrige Geschwindigkeit des Zahlenaustauschs zwischen RAM und externen Speichergeräten;
- eine relativ kleine RAM-Kapazität mit einer sehr großen Kapazität externer Speichergeräte;
- die Möglichkeit zufälliger Ausfälle der Maschine und die daraus resultierende Notwendigkeit, ihren Betrieb zu überwachen.
Programmierung. Programmierung ist in Aufzeichnung des entwickelten Algorithmus in einer Programmiersprache (z. B. in der sogenannten ASSEMBLY-Sprache oder in ALGOL, FORTRAN, COBOL, PL/I), manuell durchgeführt, und anschließende Übersetzung in eine maschinelle Algorithmensprache.
Übertragung ist der Prozess der äquivalenten Transformation eines in einer Programmiersprache gegebenen Algorithmus in einen Algorithmus in einer Maschinensprache. Dieser Vorgang wird mit einem speziellen Programm namens Übersetzer durchgeführt.
Debuggen des Programms auf der Maschine. Das Debuggen eines Programms auf einer Maschine zielt darauf ab, Fehler im Programm zu beseitigen und umfasst: Programmsteuerung; Suche und Bestimmung des Inhalts (Diagnose) von Fehlern; Korrektur gefundener Fehler.
Vorbereitung der Ausgangsdaten. Lösen eines Problems auf einem Computer. Die Ausgangsdaten der in den Computer einzugebenden Aufgabe müssen zuvor von Formularen oder Dokumenten auf Lochstreifen oder Lochkarten übertragen werden. Dieser Vorgang wird auf speziellen Perforiergeräten durchgeführt, die mit einer Tastatur ausgestattet sind. BEI Beim Perforationsprozess sind Fehler sowohl als Ergebnis zufälliger Ausfälle von Perforiervorrichtungen als auch als Ergebnis von Fehlern in der Arbeit von Perforierpersonal möglich. Alle Fehler, die während der Perforation und Eingabe in die Informationen eingeführt wurden, müssen korrigiert werden.
In der Regel werden entweder 80-Spalten-PCs oder eine Papier-PL verwendet, um Informationen in einen Computer einzugeben. Größere Maschinen haben beides. Eine Lochkarte enthält 12 Zeilen, daher sind in jeder Spalte 12 Lochungen möglich; in Querrichtung des Lochstreifens sind 5, 6, 7 und 8 Lochstellen erlaubt. So ist es theoretisch möglich, ein Alphabet von 2 5 = 32 bis 2 12 = 4096 Zeichen zu verwenden, aber in der Praxis sind selten mehr als 3 Lochungen in einer Lochkartenspalte, so dass das verwendete Alphabet in der Regel aus enthält 40 bis 80 Zeichen. Unter den Computerausrüstungen gibt es ein unabhängiges Gerät zum Reproduzieren von Informationen auf Papier, die auf Lochkarten und Lochstreifen in einer für das menschliche Lesen bequemen Form enthalten sind. Als Ergebnis erhalten wir das, was normalerweise genannt wird Auflistung oder Ausdruck.
Nach Eingabe der Programme und Anfangsdaten in den Computer wird das Problem automatisch gelöst.
Computer Software
Mathematische Software (MO) des Computers kann als eine Sammlung von Programmen definiert werden, die vom Benutzer einzeln oder in Kombination mit einigen anderen Programmen praktisch verwendet werden können, um Probleme zu lösen oder einige Arbeiten im Zusammenhang mit der Programmierung auszuführen oder um eine bestimmte Betriebsart des Computers zu erstellen.
BEI MO-Computersystem kann die folgenden Programmgruppen umfassen:
Betriebssystemprogramme;
Software System;
Anwendungen für Programme;
Software-Support-Softwaresystem;
ein System von Testprogrammen zur Überwachung des Zustands des Computers.
Operationssystem enthält Programme, die die Arbeitsweise des Computers bestimmen und seine Einsatzmöglichkeiten erweitern. Teil Betriebssystem enthält eine Reihe von Programmen, von denen die folgenden die wichtigsten sind:
Dispatcher- ein Programm, das eine bestimmte Betriebsart des Computers bereitstellt;
Aufsicht, oder Monitor,- ein Programm, das der Maschine von einem menschlichen Bediener im Rahmen des dafür festgelegten Modus Arbeit gibt;
eine Reihe von Hilfsprogrammen, z. B. Programme zum Eingeben von Anfangsdaten, Programme zum Bearbeiten und Ausgeben von Ergebnissen, ein Lader - ein Programm zum Eingeben sogenannter Arbeitsprogramme in den RAM, dh Programme zum Lösen von Problemen, ein Bibliothekar - ein Programm für Eingabe von Subroutinen zum Ausführen von Makrooperationen und selbst Subroutinen von Makrooperationen, ein Programm zur Kommunikation zwischen dem Betriebssystem und dem menschlichen Operator.
Für den Betrieb des Betriebssystems sehr wichtig haben die Merkmale, die moderne Maschinen haben (und die die Maschinen der ersten Generation nicht hatten): das Vorhandensein eines Interrupt-Systems, Speicherschutz, Befehlsschutz und Interrupt-Maskierung.
Das Wesen des Dispatchers liegt darin, dass er jede Unterbrechung des Betriebs der Maschine entweder auf die Anzahl der taktischen bezieht und in diesem Fall die Kontrolle und Information über die Unterbrechung sofort an den Vorgesetzten übergibt, oder auf die Anzahl der strategischen. Im letzteren Fall gibt es den Interrupt selbst frei. Der dieser Reaktion entsprechende Text wird als Schluss bezeichnet.
Der Supervisor plant auf Wunsch des menschlichen Bedieners die Reihenfolge der Ausführung von Programmen und verteilt die verfügbare Computerausrüstung zwischen ihnen, organisiert ihre Warteschlange und hält die Ordnung in dieser Warteschlange aufrecht. Die Hauptaufgaben des Supervisors sind: Verwaltung des Fortschritts des Computers; Aufrechterhaltung des Kontakts mit dem menschlichen Bediener.
Es gibt verschiedene Betriebsmodi des Computers, deren Bereitstellung einer der Hauptzwecke des Dispatchers ist.
Eine Reihe von Modi sind mit der Lösung von Problemen verbunden, die in Form des sogenannten dargestellt werden Arbeitspaket. Gleichzeitig wird das Gesamtpaket mit Informationen über die darin enthaltenen Aufgaben und deren Vorteile untereinander versorgt (Prioritätensystem).
Die Ausführung des Arbeitspakets erfolgt unter der Kontrolle des Vorgesetzten. Dabei kann ein Einprogramm-, Zweiprogramm- oder Mehrprogrammbetrieb der Maschine durchgeführt werden. Die Effektivität seiner Verwendung hängt weitgehend davon ab, wie die Arbeit zu einem Paket zusammengefasst wird. Ein Paket gilt als gut, wenn die CPU (Recheneinheit und Steuereinheit) nicht im Leerlauf ist. Die beschriebenen Modi werden aufgerufen Batch-Modi. Moderne Computer erlauben die gleichzeitige Ausführung von bis zu 16 Jobs.
Time-Sharing-Modus dadurch gekennzeichnet, dass eine große Anzahl entfernter Eingabe-Ausgabe-Geräte, Terminals genannt, gleichzeitig mit dem Computer verbunden sind. Während im Stapelbetrieb die Benutzer das Bedienfeld nicht betreten dürfen, kommuniziert im Time-Sharing-Modus jeder von ihnen ohne Beteiligung des Bedieners mit der Maschine. Der Dispatcher stellt sicher, dass allen in der Warteschlange befindlichen Benutzern konsistent kleine Zeitabschnitte gewährt werden. Über einen Zeitraum von wenigen Sekunden bedient die Maschine jeden Benutzer nach und nach. Der Time-Sharing-Modus ist in Fällen praktisch, in denen die Ausführung von Maschinenarbeit in Form eines Dialogs zwischen dem Computer und dem Benutzer ablaufen soll. Ego findet beim Debuggen von Computerprogrammen statt, beim Lösen von Informationsproblemen wie Frage-Antwort.
Software System enthält eine Reihe von Übersetzerprogrammen zum Übersetzen von Algorithmen, die in verschiedenen Eingabeprogrammiersprachen angegeben sind, in Maschinensprache. Typischerweise enthält ein Programmierwerkzeugsystem Übersetzer aus drei Ebenen algorithmischer Sprachen.
Der Prozess der Übersetzung eines Algorithmus und der Prozess seiner Ausführung durch eine Maschine können auf zwei Arten kombiniert werden.
Die erste Methode namens Zusammenstellung, besteht darin, dass der Prozess der Ausführung des Algorithmus durch die Maschine ausgeführt wird, nachdem der Prozess seiner Übersetzung vollständig abgeschlossen ist. Der Name "Kompilierung" entstand aufgrund der Tatsache, dass ursprünglich der Übersetzungsprozess gemeint war, basierend auf der Kombination von vorbereiteten Teilen (Subroutinen), die bestimmten Teilen des übersetzten Algorithmus entsprechen, zu einem einzigen Ganzen. Anschließend wurde dieser Name auf den Fall der "dynamischen" Übersetzung erweitert, die nicht mit der Verwendung vorgefertigter Texte verbunden ist.
Die zweite Möglichkeit, den Übersetzungsprozess und den Algorithmusausführungsprozess zu kombinieren, wird aufgerufen Interpretation. Dieses Verfahren besteht darin, dass einzelne Teile des Algorithmus unmittelbar nach der Übersetzung durchgeführt werden, wonach die gleiche Prozedur an anderen Teilen des Algorithmus durchgeführt wird usw.
Die Kompilierung zeichnet sich dadurch aus, dass das Compilerprogramm, das sie während der Ausführung des Algorithmus implementiert, nicht mehr benötigt wird und sich daher nicht im Hauptspeicher des Computers befindet. Die Anwendung des Interpretationsverfahrens erfordert das Vorhandensein eines Interpreterprogramms im Hauptspeicher des Computers während der Lösung des Problems.
Jede der Methoden hat ihre eigenen Vorteile, aber die Interpretationsmethode ist flexibler. Außerdem vereinfacht es die Aufgabe des Zuordnens von Speicher, obwohl es viel zusätzlichen Speicher erfordert, um das Interpretierungsprogramm selbst zu speichern.
Die Softwaresysteme neuester Computer basieren häufig auf dem sogenannten Modularitätsprinzip. Module werden als "Teile" von Algorithmen bezeichnet, die in der Sprache des ausführenden Systems oder in der Eingabeprogrammiersprache angegeben sind, für die die folgenden Bedingungen erfüllt sind:
In der Sprache des Exekutivsystems spezifizierte „Stücke“ von Algorithmen müssen mit ausreichenden Zusatzinformationen versehen werden, um sicherzustellen, dass bei ihrer entsprechenden Verarbeitung daraus ein in der Sprache des Exekutivsystems spezifiziertes Programm zusammengesetzt werden kann;
„Stücke“ von Algorithmen, die in den Eingabeprogrammiersprachen spezifiziert sind, müssen mit zusätzlichen Informationen versorgt werden, die ausreichen, um sie in Module umwandeln zu können, die in der algorithmischen Sprache des Exekutivsystems mit entsprechender Verarbeitung spezifiziert sind.
Modularitätsprinzip besteht darin, dass Programme in der Sprache des Exekutivsystems aus Modulen zusammengesetzt werden. Module in der Sprache des Exekutivsystems können in der Bibliothek akkumuliert werden. Das Baukastenprinzip erlaubt die Verwendung von in verschiedenen algorithmischen Sprachen kompilierten Modulen beim Zusammenstellen eines Programms. Die Möglichkeit, Module zu akkumulieren und wiederzuverwenden, spart Programmierern Arbeit.
Alle Softwareprogramme müssen Mitglieder einer Bibliothek sein. Bibliothek von Standardprogrammen ist eine Sammlung von vorkompilierten Programmen, in der jedes Programm mit zusätzlichen Informationen versehen ist, die es identifizieren. Daten zu allen Programmen sollten in einer gemeinsamen Tabelle namens zusammengefasst werden Verzeichnis. Das Verzeichnis sollte es Ihnen ermöglichen, eine Subroutine anhand ihres Namens und ihres Zwecks zu finden.
Die Bibliothek sammelt normalerweise speziell kompilierte und speziell entworfene Programme.
Die aufgeführten Programmierwerkzeuge sollen zur Lösung verschiedener Aufgaben (Probleme) eingesetzt werden. Gleichzeitig wird berücksichtigt, dass die Programme einzelner Aufgaben (Probleme) möglicherweise nicht sehr „gut“ sind, der Gesamtaufwand für das Programmieren und Lösen eines Problems am Computer jedoch normalerweise geringer ist als beim Erstellen von mehr „gut“. Programme.
Mathematische Unterstützung von ACS
Mathematische Unterstützung (MO) ACS- Dies ist ein System von Methoden, Techniken und Werkzeugen, mit denen Sie Programme zur Lösung spezifischer Probleme automatisierter Steuersysteme auf einem Computer effektiv entwickeln, den Betrieb eines Computers bei der Lösung dieser Probleme steuern und den korrekten Betrieb von steuern können ein Computer.
Die wichtigsten Bestimmungen, die bei der Erstellung eines MO ACS befolgt werden müssen, sind die folgenden:
- Kompatibilität und Basis des entwickelten MO ACS auf dem bestehenden MO-Rechner;
- die Ausrichtung der gewählten Mittel des MD auf die Aufgaben des automatisierten Steuerungssystems;
- eine ausreichende Auswahl an Programmierautomatisierungstools;
- die Fähigkeit, effektiv Änderungen an Arbeitsprogrammen vorzunehmen;
- die Möglichkeit einer eindeutigen und erschöpfenden Beschreibung von Algorithmen;
- die Möglichkeit, die Arbeit von Programmen für den privaten Gebrauch zu optimieren;
- Modularität von Bauprogrammen.
MO ACS dient dazu, dem Nutzer ein breites Spektrum an Dienstleistungen rund um die Programmiertechnik zur Verfügung zu stellen. Es kann in zwei Teile unterteilt werden: Erstellen von Steuerprogrammen und Erstellen von Verarbeitungsprogrammen.
Steuerprogramme Führen Sie das anfängliche Laden des RAM der Maschinen und die Steuerung der Arbeit des automatisierten Steuersystems durch, einschließlich der Verarbeitung von Interrupts, der Verteilung der Arbeit der Kanäle, des Ladens von Programmen aus der Bibliothek in den RAM. Steuerprogramme bieten Multiprogrammarbeit und kommunizieren mit dem Bediener.
Programme verarbeiten umfassen ein Progrund Serviceprogramme.
Funktionen des Programmierautomatisierungssystems Folgendes: Schreiben von Programmen in Eingabeprogrammiersprachen; Übersetzung von Programmen in die interne Sprache des Computers; Assoziation (Assemblierung) der notwendigen Konfigurationen (Segmente) aus Standardroutinen; Debuggen von Programmen auf der Ebene von Eingabesprachen; Korrektur von Programmen auf der Ebene der Eingabesprachen.
Die Hauptaufgaben von Serviceprogrammen sind wie folgt: Schreiben von Programmen in die Bibliothek; Ausschluss von Programmen aus der Bibliothek; Umschreiben von Programmen von einem Magnetmedium auf ein anderes, Drucken und Ausgeben von Programmen auf Lochmedien; Aufrufen der erforderlichen Programme während des Arbeitsvorgangs im RAM und Einrichten an seinem Speicherort.
Die Hauptkomponenten von MO ACS sind ein System-Dispatcher-Programm und eine Bibliothek von Standard-Subroutinen und Standardprogrammen zur Verarbeitung von Produktions- und Wirtschaftsinformationen.
System-Dispatcher gewährleistet das Funktionieren des automatisierten Kontrollsystems in dem Modus, der durch die Produktions- und Wirtschafts- oder Verwaltungstätigkeit bestimmt wird.
Bibliothek von Standardroutinen, in MO-Computern verfügbar ist, ist ein Übergangsschritt zur Entwicklung einer Systembibliothek, die sich auf Iin automatisierten Steuerungssystemen konzentriert. Systembibliothek muss enthalten:
Programme zur Eingabe und Konvertierung von Dokumenten und anderen schriftlichen Ausgangsdatenquellen in Maschinenform;
Programme zum Organisieren von Computer-Arrays, die sowohl durch große Volumina als auch durch die Komplexität ihrer Struktur gekennzeichnet sind, zum effizienten Suchen und Extrahieren der erforderlichen Daten aus Arrays;
Programme zum Konvertieren von Daten in die benutzerfreundlichste Form (in Form von Grafiken, Diagrammen, Bildern) und deren Ausgabe an externe Geräte.
Programmiersprachen
Programmiersprache sogenannte Zeichensysteme, mit denen die Prozesse zur Lösung von Problemen auf einem Computer beschrieben werden. Programmiersprachen werden ihrer Natur nach in drei Gruppen eingeteilt:
- formale algorithmische Sprachen;
- formale nicht-algorithmische Programmiersprachen;
- nicht ganz formalisierte Zeichensysteme, die in der Programmierung verwendet werden.
Formale Programmiersprachen. Diese Gruppe von Sprachen umfasst: algorithmische Sprachen von Maschinen und Betriebssystemen; maschinenorientierte algorithmische Sprachen; problemorientierte algorithmische Sprachen; universelle maschinenunabhängige algorithmische Sprachen.
Betriebssystemsprachen Algorithmische Sprachen werden algorithmische Sprachen genannt, die von Komplexen wahrgenommen werden, die aus einem Computer und einem für sie entwickelten Dispatcher-Programm (manchmal auch Supervisor genannt) gebildet werden.
Programme direkt von Hand in der Sprache der Maschine oder des Betriebssystems zu kompilieren, wird derzeit nicht verwendet, da der Programmierer sich eine große Anzahl von Details merken muss, ohne die es unmöglich ist, ein Programm aus Befehlen zu erstellen.
Maschinenorientierte algorithmische Sprachen enthalten aussagekräftige Mittel, mit denen Sie in der Aufzeichnung des Algorithmus angeben können, mit welchen technischen Mitteln bestimmte Teile davon ausgeführt werden sollen und wie Speichergeräte in diesem Fall verwendet werden sollen. Zu den maschinenorientierten Programmiersprachen gehören Autocodes und einige Sprachen, die in ihren Fähigkeiten universellen algorithmischen Sprachen nahe kommen, wie z. B. ALMO.
Domänengesteuerte algorithmische Sprachen Dies sind Sprachen, die speziell dafür entwickelt wurden, die Prozesse zur Lösung von Problemen einer bestimmten engen Klasse zu beschreiben, z. B. Probleme der linearen Algebra, Statistik, Datenverarbeitungsprobleme usw. Insbesondere COBOL gehört zu den problemorientierten Sprachen.
Universelle maschinenunabhängige algorithmische Sprachen geeignet zum Erstellen von Algorithmen zum Lösen von Problemen sehr breiter Klassen. Zu diesen Sprachen gehören die bereits erwähnten ALGOL, FORTRAN, PL/1.
Unter den universellen maschinenunabhängigen algorithmischen Sprachen ist YLS die Ausnahme. Der Zweck dieser Sprache ist nicht darauf beschränkt, eine Programmiersprache zu sein. YALS wird als erste Stufe der Beschreibung von Algorithmen bei der Programmierung in Maschinensprache oder in ASSEMBLY-Sprache verwendet (Operator-Programmiermethode; der in YALS geschriebene Algorithmus wird manuell in Maschinensprache oder ASSEMBLY-Sprache übersetzt).
Die folgende Tabelle bietet einen Vergleich formaler Programmiersprachen.
Nicht ganz formalisierte Zeichensysteme. Diese Sprachen werden typischerweise in der manuellen Programmierung oder im manuellen Vorschritt der automatisierten Programmierung verwendet. Ein Beispiel hierfür ist ein Programmablaufplan. Das Blockdiagramm des Programms ist eine erweiterte Beschreibung des Programms, in der seine einzelnen Teile in Form von "Blöcken" (Rechtecke, Rauten, Kreise usw.) dargestellt sind, innerhalb derer der Inhalt dieser Teile in a angegeben ist natürliche Sprache (z. B. Russisch). Die Kommunikation zwischen Blöcken (Teilen des Programms) wird mit Hilfe von Linien dargestellt, die die Übergabe der Kontrolle bezeichnen. Die Linien können beschriftet sein, um die Bedingungen anzuzeigen, unter denen die Steuerungsübertragung stattfindet. Blockdiagramme ähneln Algorithmen, die in LLS unter Verwendung verallgemeinerter Operatoren geschrieben wurden, unterscheiden sich jedoch von ihnen darin, dass die Bedeutung der Blöcke in einer natürlichen, informellen Sprache angegeben wird, während in LLS verallgemeinerte Operatoren in einer exakten formalen Sprache decodiert werden.
Derzeit sind mehr als 2000 verschiedene algorithmische Sprachen und mehr als 700 Bereiche ihrer Anwendung bekannt, um die entsprechenden Probleme auf einem Computer zu lösen.
Es gibt Programmiersprachen der folgenden Ebenen:
Null- oder niedrigere Sprachebene - Maschinencode;
die Sprache der ersten Ebene ist der Mnemocode oder die Sprache der symbolischen Codierung;
Sprache der zweiten Ebene - Autocode (Makrocode);
Sprachen der dritten Ebene (höher) - problemorientierte Sprachen.
Als Eingabesprachen empfiehlt es sich, je nach Art der Aufgaben des automatisierten Steuerungssystems zu verwenden domänenspezifische Sprachen verschiedene Arten
Vergleichsdaten formaler algorithmischer Programmiersprachen
|
Klasse algorithmischer Programmiersprachen |
Abrechnung von Computerfunktionen |
Merkmale der Aufgabenklasse |
Programmierweise |
Bedingte Bewertung der Programmqualität |
|
Maschinensprachen |
||||
|
Maschinenorientierte Sprachen |
Teilweise |
Bestimmt durch die Funktionen des Computers |
automatisiert |
Zufriedenstellend |
|
Domänenspezifische Sprachen |
Unerheblich |
automatisiert |
Zufriedenstellend |
|
|
Universelle maschinenunabhängige Sprachen |
Keine oder sehr wenig |
Sehr umfangreich |
automatisiert |
niedrig |
(zum Beispiel für die Analyse - ALGOL, FORTRAN usw., für wirtschaftliche Probleme - ALGEK usw., für Informationsprobleme - COBOL, SYNTOL usw.).
Betrachten Sie einige der algorithmischen Programmiersprachen.
ALGOL-60. Der Name der Sprache kommt von englische Wörter Algorithmische Sprache. Es wurde 1960 von einer Gruppe von Wissenschaftlern aus verschiedenen Ländern entwickelt und ist weit verbreitet. Die Gründe für den Erfolg sind die Nähe zur üblichen mathematischen Sprache, die Bequemlichkeit, eine breite Klasse von Problemen zu beschreiben, Universalität und vollständige Unabhängigkeit von einem bestimmten Computer, strenge Formalisierung der Sprache vom Alphabet bis zu den komplexesten Strukturen.
ALGOL-60 ist nicht nur eine universelle Programmiersprache, sondern auch eine internationale Sprache zur Beschreibung von Algorithmen.
Die Grundlage für das Schreiben von Algorithmen in der ALGOL-60-Sprache ist eine Folge von Operatoren, die durch das Symbol ";" getrennt sind. Zu dieser Folge von Anweisungen, die einzelne Aktionen in der Sprache sind, gesellt sich eine Folge von Beschreibungen, die dem Übersetzer Informationen über die in den Anweisungen verwendeten notwendigen Eigenschaften geben. Beschreibungen geben zum Beispiel Auskunft über die Klassen von Zahlen, die als variable Werte verwendet werden, über die Dimensionen von Zahlenfeldern usw. Eine solche Kombination von Beschreibungen und Operatoren wird in dieser Sprache als Block bezeichnet.
Ein Programm in der ALGOL-60-Sprache ist ein Block oder eine zusammengesetzte Anweisung, die keine andere Anweisung enthält und keine andere Anweisung verwendet, die nicht darin enthalten ist.
Rechenzentren, in denen ALGOL-Programmierungen durchgeführt werden, sollten Erfahrungen nicht in Form von vollständigen ALGOL-Programmen, sondern in Form von Verfahrensbeschreibungen sammeln. Dies liegt daran, dass es praktisch unmöglich ist, vorgefertigte ALGOL-Programme in neue Programme einzubinden, während die Verfahrensbeschreibungen speziell darauf ausgelegt sind.
In der UdSSR verbreitete sich ALGOL-60 in Form einiger seiner Varianten.
FORTRAN. Das Wort FORTRAN wird aus zwei englischen Wörtern gebildet (Formula Translator). Eines der wichtigsten Merkmale der FORTRAN-Sprache ist, dass sie relativ frei von den Besonderheiten eines bestimmten Computers ist. FORTRAN ist eine maschinenunabhängige Programmiersprache.
Die umfangreichsten mathematischen Softwarebibliotheken in dieser Sprache wurden angesammelt, darunter sowohl Standardprogramme (häufig verwendete) als auch viele Spezialprogramme, die zur Lösung spezifischer Probleme verwendet werden.
Die weit verbreitete Einführung von FORTRAN in die Programmierpraxis ist auf seine Qualitäten zurückzuführen, von denen erstens seine Einfachheit im Vergleich zu anderen algorithmischen Sprachen (z. B. ALGOL) zu erwähnen ist; zweitens sind übersetzte Programme aufgrund des Fehlens übermäßig komplexer Strukturen effizienter als in anderen Sprachen geschriebene Programme; gleichzeitig ist FORTRAN zum Programmieren der meisten Rechenalgorithmen geeignet;
Drittens verfügt FORTRAN über sehr leistungsfähige Mittel, um eine Person mit einer Maschine zu verbinden: Die von einem Computer ausgegebenen Informationen werden in einer Form präsentiert, die Wissenschaftlern und Ingenieuren vertraut ist. Und schließlich, viertens, ist FORTRAN gut geeignet für die effiziente Nutzung externer Computergeräte.
Der mit FORTRAN geschriebene Algorithmus zur Lösung des Problems besteht aus einer Folge von Operatoren. Diese Operatoren können von mehreren unterschiedlichen Typen sein. Zusammengenommen bilden die Operatoren, die den Algorithmus zur Lösung des Problems bestimmen, das ursprüngliche Programm. Nachdem das Quellprogramm geschrieben und auf Lochkarten gestanzt wurde, wird es unter Verwendung eines FORTRAN-Übersetzers in ein Arbeitsprogramm umgewandelt.
Der erste Operator ist der Header-Operator, der wie folgt aussieht: || PROGRAMM ||, wobei a der Name des Programms ist und der letzte der Endeoperator (Operator || END ||) und eine Reihe von Unterroutinen ist. Das Hauptprogramm und jede Subroutine lokalisieren die Labels von Anweisungen sowie die Namen von Variablen, Arrays und anderen Werten, wodurch die Verwendung derselben Labels und Identifikatoren in verschiedenen Subroutinen und im Hauptprogramm ermöglicht wird. Die Kommunikation zwischen Hauptprogramm und Unterprogrammen erfolgt über die entsprechenden Aufrufoperatoren.
Beim Kompilieren von Programmen in FORTRAN wird empfohlen, die folgende Reihenfolge der Operatoren einzuhalten: 1) Operator-Überschrift des Hauptprogramms (Unterprogramm); 2) Dateibeschreibungsoperator; 3) impliziter Typzuweisungsoperator; 4) ein expliziter Operator zum Spezifizieren eines Typs, ein Operator zum Spezifizieren von Dimensionen, ein Operator zum Spezifizieren gemeinsamer Bereiche; 5) Äquivalenzspezifikationsoperator; 6) Operatorfunktion, Operatorprozedur; 7) Formatsetzoperator, ausgeführte Operatoren (unbedingt, bedingt, Eingabe, Ausgabe); 8) Endoperator.
COBOL. Der Name der Sprache leitet sich von den englischen Wörtern Common Business Orientated Language ab. COBOL ist eine problemorientierte algorithmische Sprache, die entwickelt wurde, um die Prozesse der Problemlösung und Datenverarbeitung zu beschreiben. COBOL ist derzeit die einzige weit verbreitete Sprache hohes Level für die Programmierung betriebswirtschaftlicher Aufgaben. Seine große Popularität erklärt sich aus der Tatsache, dass COBOL der natürlichen Sprache, in der wirtschaftliche Probleme üblicherweise formuliert und gelöst werden, recht nahe kommt.
Die Besonderheiten der COBOL-Sprache sind wie folgt:
Sprache ist gewissermaßen eine Teilmenge auf Englisch; in COBOL geschriebener Text kann ohne vorherige Vorbereitung verstanden werden;
die Sprache beschreibt Daten gut mit einer für Geschäftspapiere typischen Struktur; diese Daten können sich auf persönliche Angelegenheiten, Waren, Finanzen beziehen (kombinierte Daten sind ebenfalls zulässig);
in der Sprache wird versucht, das Problem der vollen Kompatibilität, d. h. der Unabhängigkeit von den Besonderheiten bestimmter Computer, zu lösen.
Ein COBOL-Programm besteht aus vier Teilen, die als Abschnitte bezeichnet werden. Diese Abschnitte haben die folgenden Namen: Identifikationsabschnitt, Ausrüstungsabschnitt, Datenabschnitt und Verfahrensabschnitt. Der Abschnitt Prozedur enthält das eigentliche Programm, aber es ist bedeutungslos (oder bestenfalls nicht vollständig definiert), wenn die Struktur der zu verarbeitenden Daten, wie sie im dritten Abschnitt definiert ist, bekannt ist. Der Hardwareabschnitt ist weiter in einen Konfigurationsabschnitt und einen E/A-Abschnitt unterteilt, während der Datenabschnitt in einen Arrayabschnitt, einen Arbeitsspeicherabschnitt und einen Konstantenabschnitt unterteilt ist. Am Anfang eines Abschnitts (Abschnitt) steht der Name des Abschnitts (Abschnitt), gefolgt von einem Punkt; der Name mit einem Punkt nimmt eine separate Zeile ein. Der Inhalt eines Abschnitts oder Abschnitts besteht aus Sätzen, die in benannten Absätzen gruppiert sind.
In COBOL ist es viel einfacher, kleine Änderungen am Programm vorzunehmen, die bei der Verarbeitung von kommerziellen Informationen erforderlich sind.
In COBOL ist die Basiseinheit der E/A die Datendatei. Jede Datei besteht aus Datensätzen. Dieselbe Datei wird häufig in verschiedenen Programmen verwendet, je nach Art der zu lösenden Aufgaben. Die Beschreibung der Dateien ist sehr streng und kann nicht geändert werden.
Die Entwickler berücksichtigten die Möglichkeit, eine Maschine zum Senden von Programmen und eine andere Maschine zum Lösen des Problems gemäß dem kompilierten Programm zu verwenden. Darüber hinaus kann dasselbe COBOL-Programm in die Sprachen verschiedener Computer mit unterschiedlicher Ausstattung übersetzt werden.
SOL. Digitale Simulation als effektive Methode Forschung gewinnt immer mehr an Popularität unter Spezialisten, die sich mit der Analyse und dem Entwurf komplexer Systeme befassen.
Sehr oft hat ein Systemspezialist Schwierigkeiten, ein Programm zu schreiben, das den Betrieb des Systems simuliert, das er studiert. Grund dafür kann die extreme Komplexität mathematisch kaum beschreibbarer Systeme sein. Probleme dieser Art gibt es insbesondere in der Praxis der Erstellung von Instrumentierungs- und Steuerungssystemen. Um das Kompilieren von Programmen zu erleichtern, werden derzeit automatische Programmiersprachen (spezialisierte Modellierungssprachen) verwendet, die es ermöglichen, mit dem geringsten Zeitaufwand für die Vorbereitung und Implementierung von Aufgaben auf einem Computer Programme zu erstellen und zu untersuchen, die den Betrieb des Systems simulieren im Studium.
Dabei sind die Elemente einer Fachsprache in der Regel recht universell und können es sein . angewendet auf eine breite Klasse von simulierten Phänomenen. Darüber hinaus vereinfachen spezialisierte Modellierungssprachen im Vergleich zu universellen die Programmierung von Rechen- und Logikoperationen, die das zu modellierende System charakterisieren, erheblich. Gleichzeitig wird auch die Verbindung zwischen dem Taskmanager und dem Programmierer vereinfacht. Dies wird durch die folgenden Merkmale spezialisierter Modellierungssprachen erreicht:
- die Fähigkeit, die Struktur der Speicherzuordnung der Maschine zwischen Variablen und Parametern festzulegen. Diese Verteilung ist feinkörniger und raffinierter als die, die mit den meisten universellen Sprachen erreicht wird;
- das Vorhandensein eines Satzes von Anweisungen, die die Zustandsänderung des simulierten Systems vereinfachen. In den meisten Fällen erfolgt dies durch eine Standardsteuerung oder ein temporäres Unterprogramm, das die Reihenfolge steuert, in der die Unterprogramme implementiert werden;
- das Vorhandensein einer Reihe von Anweisungen, die die Notwendigkeit der Implementierung einer bestimmten Subroutine zu einem bestimmten Zeitpunkt bestimmen;
- das Vorhandensein von Befehlen zum Ausführen standardmäßiger oder häufig auftretender Operationen in Bezug auf Zufallszahlen und Wahrscheinlichkeitsverteilungen;
- das Vorhandensein von Befehlen, die den Empfang und die Registrierung statistischer Indikatoren während der Ausführung des Modellierungsprogramms vereinfachen.
Betrachten Sie einige spezialisierte algorithmische Modellierungssprachen.
Die universelle Modellierungssprache GPSS ist die am weitesten verbreitete, einfachste und intuitivste. Es erfordert keine Kenntnisse in Programmierung und Maschinenbedienung. Der Simulator wird in Form eines Blockdiagramms dargestellt, was besonders für Nicht-Programmierer attraktiv ist.
Die algorithmische Sprache SIMSCRIPT gilt derzeit als die mächtigste Modellierungssprache. Aufgrund einer Reihe einzigartiger Merkmale ist es für die breiteste Klasse von Aufgaben anwendbar. Diese Sprache ist jedoch relativ komplex, und Diagnosewerkzeuge zum Debuggen von Programmen sind begrenzt. Darüber hinaus muss ein potenzieller Benutzer dieser Sprache FORTRAN kennen und Programmiererfahrung haben.
Die Aufmerksamkeit von Spezialisten, die an der Lösung von Modellierungsproblemen beteiligt sind, wird durch spezialisierte Sprachen auf sich gezogen, die zu diesem Zweck auf der Grundlage von ALGOL entwickelt wurden. Unter diesen automatischen Programmiersprachen sind SIMULA und SOL (SOL) die fortschrittlichsten.
Ein Beispiel für eine der erfolgreichsten spezialisierten algorithmischen Sprachen zur Modellierung diskreter Systeme ist die Simulation Orientated Language (SOL).
Die Sprache SOL ist auf Basis der universellen Programmiersprache ALGOL aufgebaut, hat die gleiche Struktur und verwendet deren Hauptelemente. Um eine breite Klasse von Prozessen mit diskreten Ereignissen zu beschreiben, stellt SOL ein universelles System von Konzepten dar und ist daher in vielerlei Hinsicht domänenorientierten automatischen Programmiersprachen wie ALGOL oder FORTRAN sehr ähnlich. Die SOL-Sprache weist jedoch die Hauptmerkmale auf, die sie von diesen Sprachen unterscheidet: SOL bietet einen Mechanismus zum Modellieren asynchroner paralleler Prozesse, eine praktische Notation für zufällige Elemente innerhalb arithmetischer Ausdrücke und automatische Tools zum Sammeln statistischer Daten über die Komponenten des simulierten Systems. Andererseits werden viele Funktionen domänenspezifischer universeller Sprachen in SOL nicht verwendet, nicht weil sie damit inkompatibel sind, sondern weil sie dem Design eine große Komplexität hinzufügen, ohne seine Fähigkeiten zu erweitern. Die Prinzipien, die der Konstruktion der Sprache und dem Schreiben von Simulationsprogrammen zugrunde liegen, ermöglichen das Erstellen von Modellen komplexer Systeme in einer leicht lesbaren Form.
PL/ich. Der Name der Sprache kommt von den englischen Wörtern Programming Language/One.
Die PL/I-Sprache erschien nach der Schaffung einer Reihe hochentwickelter Sprachen, und natürlich hatten diese Vorgängersprachen einen erheblichen Einfluss auf ihre Struktur. So behält es die Blockstruktur des Programms von ALGOL bei, die Möglichkeit der dynamischen Speicherzuordnung, es gibt einen Apparat zum Aufrufen von Prozeduren, eine Methode zum Setzen von Formaten, die in FORTRAN verwendet werden, usw. Aber es gibt auch viele neue Funktionen. Die Sprache eignet sich zum Modellieren und Lösen logische Aufgaben, Erforschung logischer Schaltungen, Problemlösung in Echtzeit, Entwicklung von Softwaresystemen. Mögliche Verwendung Anderer Typ Daten (binäre, dezimale, symbolische, komplexe Zahlen, Matrizen usw.), aber es ist sehr schwierig, diese Daten in Arrays, Tabellen, Texte, Fragebögen, Aktenschränke usw. zu organisieren. Es gibt eine große Menge an Standardfunktionen und -prozeduren. In der PL/I-Sprache wurde ein erfolgreiches Operationssystem entwickelt, das alle Prozesse der Eingabe, Ausgabe und des Austauschs von Informationen zwischen Haupt- und Speichergeräten steuert. All diese Merkmale erwecken den Eindruck einer starken Überlastung der Sprache. Auch die Nachteile sind zu beachten: Die Beschreibung der Sprache ist unbefriedigend, sie ist nicht formalisiert.
PL/I ist eine Mehrzweck-Programmiersprache, die nicht nur für die wirtschaftliche und wissenschaftlich-technische Programmierung, sondern auch für die Programmierung von Echtzeitjobs und für die Erstellung von Programmiersystemen entwickelt wurde.
Eines der Hauptziele bei der Entwicklung der Sprache war die Modularität, d. h. die Möglichkeit, bereits übersetzte Programme im Hauptprogramm als separate Module ohne erneute Übersetzung zu verwenden. Dem Bedürfnis nach größtmöglicher Einfachheit und Bequemlichkeit beim Schreiben von Programmen wurde Rechnung getragen. Gleichzeitig besteht weiterhin die Notwendigkeit, allgemeine und detaillierte logische Schemata von Programmen zu erstellen, aber mit entsprechender Erfahrung in der Programmierung in der Sprache PL / I kann man viel und mühsame Arbeit vermeiden, die mit dem Schreiben eines Programms in Maschinensprache verbunden ist.
In der PL/I-Sprache wird jedem Variablendeskriptor, jeder Spezifikationsergänzung und jeder Spezifikation eine "Interpretation (Prinzip) der Standardeinstellung" gegeben. Das bedeutet, dass überall dort, wo die Sprache mehrere Features bereitstellt und der Programmierer keine angegeben hat, der Compiler die "Standardinterpretation" verwendet, dh einige der Features, die in der Sprache für diesen Fall bereitgestellt werden, sind impliziert. Wie für jedes Konstrukt impliziert, sind die Möglichkeiten in der Sprache diejenigen, die am wahrscheinlichsten vom Programmierer benötigt werden.
PL/I-Programme werden in freier Form geschrieben; der Programmierer selbst kann die Formen des Schreibens von Programmen entwickeln, die er benötigt. Gleichzeitig wird der Zugriff auf alle Mittel des Computersystems bereitgestellt.
Die Anweisungen eines in der Sprache PL/I geschriebenen Programms werden zu "Blöcken" zusammengefasst. Blöcke leisten wichtige Funktionen: Sie definieren den Gültigkeitsbereich von Variablen und anderen Namen, sodass derselbe Name in verschiedenen Blöcken für unterschiedliche Zwecke verwendet werden kann; Sie ermöglichen es Ihnen, Speicherzellen für Variablen nur während der Ausführung eines bestimmten Blocks zuzuweisen und sie nach Beendigung des Blocks für andere Zwecke freizugeben.
ROLLENSPIEL. Die RPG-Sprache wurde entwickelt, um die Programmierung von Aufgaben und die Verarbeitung von Wirtschaftsinformationen zu automatisieren. Der Inhalt dieser Aufgaben beschränkt sich im Wesentlichen auf folgende Vorgänge: Aktenführung (d. h. Ordnen, Speichern, Korrigieren und Aktualisieren), Akten sortieren, Zusammenstellen und Drucken verschiedener Buchhaltungsunterlagen wie Listen, Aufstellungen, Tabellen, Zusammenfassungen, Berichte usw. Berechnungen nehmen in der Regel einen kleinen Teil des Gesamtvolumens der Problemlösung ein. Bei der Lösung solcher Probleme ist es zweckmäßig, das RPG zu verwenden, insbesondere in der Phase der Erstellung und Ausgabe von Berichten. In diesem Fall wird davon ausgegangen, dass die Eingabedateien, die für die Berichterstellung verwendet werden, auf andere Weise erstellt und sortiert werden.
Mit RPG können Sie einige Berechnungen (normalerweise einfache und standardmäßige) mit den Eingabedaten durchführen, einen Bericht erstellen und ihn ausdrucken. Eingabedaten können von Karteneingabegeräten, Magnetbändern oder Direktzugriffsspeichergeräten eingegeben werden. Zusätzlich zum Erstellen eines Berichts können Sie mit RPG Eingabedateien korrigieren und aktualisieren sowie neue Dateien erstellen. Das RPG verfügt über Tools, mit denen Sie Operationen mit Tabellen ausführen können (z. B. Suchen nach dem erforderlichen Element der Tabelle und Anzeigen der Tabelle), sowie Tools zum Organisieren der Verbindung des RPG-Programms mit Programmen, die in anderen Sprachen geschrieben sind und verwendet, um das gleiche Problem zu lösen.
Ein Merkmal der Sprache ist, dass der Programmierer nicht die Abfolge von Operationen zur Lösung des Problems (Problemalgorithmus) beschreiben sollte, sondern nur auf speziellen Formularen die Eingabedaten beschreiben sollte, die zum Erstellen des Berichts verwendet wurden, die Berechnungen, die mit diesen Daten durchgeführt wurden, und die Format des Berichts.
Basierend auf diesen Informationen generiert der RPG-Übersetzer ein Arbeitsprogramm, und dann verarbeitet das erstellte Programm die Eingabedateien und druckt den erforderlichen Bericht.
Die Erstellung eines Berichts mit RPG besteht aus den folgenden Hauptschritten: Definition von Aufgabendaten und deren Verarbeitung; Kompilieren des ursprünglichen Programms; Perforationen des Originalprogramms; Erhalt eines Arbeitsprogramms; Ausführung des Arbeitsprogramms.
Bevor das Programm der Aufgabe geschrieben wird, ist es erforderlich, eine Analyse davon durchzuführen. Es ist notwendig, die Eingabedaten, das Format und die Art der Eingabedatensätze, die verwendeten Datensatzfelder und ihre Position, die Art der Datenverarbeitung, die Anzahl und Art der zu berechnenden Summen, das Format des gedruckten Berichts und festzulegen andere Ausgangsdaten.
Nachdem die Eingabe- und Ausgabedaten der Aufgabe und die Methode ihrer Verarbeitung festgelegt wurden, müssen diese Daten auf den entsprechenden RPG-Formularen beschrieben werden. Es gibt verschiedene Arten von RPG-Formularen, von denen jedes dazu bestimmt ist, bestimmte Informationen aufzuzeichnen. Die Eingabedaten-Beschreibungsformulare listen alle Eingabedateien auf, beschreiben die Struktur und Unterscheidungsmerkmale aller Arten von Datensätzen in jeder der Dateien und den Ort der in den Datensätzen verwendeten Felder. Das Berechnungsformular gibt an, welche Verarbeitung der Eingabedaten durchgeführt werden muss. Das Ausgabebeschreibungsblatt beschreibt das Format des erforderlichen Berichts und anderer Ausgabedateien. Das Dateibeschreibungsformular und das Zusatzinformationsformular geben die Eigenschaften der im Programm verwendeten Dateien an (Eingabe, Ausgabe, tabellarisch usw.). Das anfängliche Programm sind die Informationen, die auf den RPG-Formularen zur Lösung dieses Problems angegeben sind.
Nachdem das Programm auf die entsprechenden Formulare geschrieben wurde, wird der Text des Programms auf die Karten gestanzt.
Um ein funktionierendes Programm zu erhalten, müssen Sie zuerst das Quellprogramm übersetzen. Zu diesem Zweck werden den Karten des Originalprogramms einige Steuerkarten hinzugefügt, z. B. die Steuerkarte des RG1G-Übersetzers und die Karten der Steueroperatoren - TASK CONTROLS, die für den Betrieb des RPG-Übersetzers erforderlich sind. Nach der Übersetzung kann das resultierende Modul mit dem EDITOR bearbeitet werden. Als Ergebnis des Editierens erhält man ein ausführbares Programm (Lademodul), das als Arbeitsprogramm bezeichnet wird. Das Zusammenstellen und Bearbeiten ist erforderlich, um den gewünschten Bericht zu erstellen.
Arbeitsprogramm kann unmittelbar nach der Übersetzung und Bearbeitung oder zu einem beliebigen anderen Zeitpunkt durchgeführt werden. Das Arbeitsprogramm liest die vorbereitenden Eingabedateien, verarbeitet sie und erhält als Ergebnis einen Bericht und andere Ausgabedateien.
ALGANEN. Die algorithmische Sprache ALGAMS konzentriert sich auf Maschinen mittlerer Leistung; seine Basis war eine Teilmenge der ALGOL-60-Sprache.
Ein wichtiges Problem, das in ALGAMS gelöst wird, ist die Einführung von Input-Output-Verfahren. In ALGAMS wurde der Satz an Standardfunktionen erweitert, es besteht auch die Möglichkeit, Bibliotheksunterprogramme zu verwenden. ALGAMS enthält Werkzeuge, mit denen Sie die mögliche Segmentierung des Programms angeben können, die sogenannten Teilekennungen, sowie Werkzeuge, die es ermöglichen, den Pufferspeicher des Computers effektiv zu nutzen, indem einige der Arrays mit speziellen Kennungen beschrieben werden.
Eine Eingabeanweisung besteht aus einem INPUT-Bezeichner, gefolgt von einer in Klammern eingeschlossenen Liste von tatsächlichen Parametern. Der erste Parameter gibt die Nummer des Kanals an, über den Daten eingegeben werden, die restlichen eigentlichen Parameter sind einfache Variablen, Array-Bezeichner oder Variablen mit Indizes.
Bei der Eingabe von Text werden aufeinanderfolgenden Elementen des Arrays, beginnend mit dem angegebenen Eingabeobjekt, ganzzahlige Werte zugewiesen, die aufeinanderfolgenden Zeichen der Eingabezeichenfolge im Sinne der Prozedur = TEXT entsprechen. Prozedur = TEXT ist wie folgt definiert:<оператор текст>::=TEXT (<строка>, <переменная с индексами>).
Die Kennung der Eingabeprozedur ist das Wort OUTPUT. Der Operator hat vier Typen: den Zahlenausgabeoperator, den booleschen Operator, den Textausgabeoperator und den Platzierungsoperator. Eine Ausgabeanweisung besteht aus einem OUTPUT-Bezeichner, gefolgt von einer in Klammern eingeschlossenen Liste von aktuellen Parametern. Der erste Aktualparameter der Prozedur definiert die Nummer des Ausgabekanals, der zweite Parameter definiert das Format der Ausgabedaten und alle anderen sind Ausgabeobjekte. Es gibt Bearbeitungswerkzeuge zum Drucken von Informationen.
BASEY K. Der Name der Sprache kommt von den englischen Wörtern Beginners All Purpose Symbolic Instructioncode. Es hat aufgrund seiner Einfachheit, Leichtigkeit des Erlernens und der großartigen Möglichkeiten zur Lösung einer Vielzahl von Problemen große Popularität erlangt. In vielen Minicomputern wird diese Sprache als Hauptsprache übernommen. Die BASIC-Sprache ist eine Programmiersprache. Es eignet sich zur Lösung wissenschaftlicher und technischer Probleme mit geringem Umfang, sowohl in Bezug auf die Anzahl der durchgeführten Operationen als auch auf die Menge der Ausgangs- und Ergebnisdaten. Das wichtigste Merkmal der Sprache ist, dass sie für eine schrittweise Implementierung geeignet ist. Das bedeutet, dass nach jeder Änderung im Quelltext eines BASIC-Programms nicht das gesamte Programm neu übersetzt werden kann, sondern nur dessen geänderte Anweisungen. Die Möglichkeit der schrittweisen Implementierung der BASIC-Sprache ermöglicht es, die Kosten für Computerzeit für die Rückübersetzung zu reduzieren. Dies wiederum beschleunigt den Debugging-Zyklus so sehr, dass es sinnvoll ist, BASIC-Programme im Dialogmodus zu debuggen.
Zusätzlich zu der Möglichkeit, große Programme zu akkumulieren, die aus neu nummerierten BASIC-Sprachoperatoren bestehen, werden sogenannte Direktbefehle bereitgestellt, dh solche, die unmittelbar nach ihrer Eingabe von der Programmiererkonsole (von einem Fernschreiber) ausgeführt werden. Im Direktkommandomodus können nicht nur administrative Direktiven wie RUN – Start der Ausführung, LIST – Textausdruck, SAVE – Speichern des Programmtextes in der Bibliothek, BYE – Ende der Sitzung verwendet werden; Jede BASIC-Anweisung, die ohne Sequenznummer eingegeben wird, wird im direkten Befehlsmodus ausgeführt. Dies ermöglicht insbesondere, die Werte von Variablen jederzeit während der Programmausführung auszudrucken und zu ändern.
Servicewort Aktion ausgeführt
PRINT In Anführungszeichen eingeschlossenen Nachrichtentext oder den Wert eines arithmetischen Ausdrucks (nach dessen Auswertung) oder die Werte von Variablen drucken
INPUT Geben Sie Zahlen von der Programmierkonsole ein und senden Sie sie an die angegebenen Variablen
LET Weist einer Variablen den Wert eines Ausdrucks zu
GO TO Geht zur Ausführung der Anweisung mit der angegebenen Nummer
IF Wenn die angegebene Bedingung erfüllt ist, muss die in diesem Operator angegebene Aktion ausgeführt werden, andernfalls gehen Sie zur Ausführung des nächsten Operators
DATEN Daten; diese Anweisung wird nicht ausgeführt. Es beschreibt einen Block von Debug-Daten (Zahlen). Der Satz von Debug-Datenblöcken bildet ein Array von Debug-Daten
ENDE Ende des Programms
Somit ermöglicht das schrittweise Kompilierungsschema in Kombination mit dem direkten Befehlsmodus ein effektives Debuggen von BASIC-Programmen im Dialogmodus.
Ein BASIC-Programm besteht aus Anweisungen, die jeweils mit einem Funktionswort beginnen. Das Dienstwort bestimmt die Art des Operators und die Art der Aktionen, die während seiner Ausführung ausgeführt werden.
Bei der Lösung vieler Probleme ist es notwendig, Daten in Form von Tabellen darzustellen. Unter Verwendung der Fähigkeiten einiger Operatoren der BASIC-Sprache ist es möglich, Tabellen verschiedener Formate zu bilden.
FORMALISIERTE SPRACHE- ein künstliches Zeichensystem, das eine Theorie darstellen soll. Eine formalisierte Sprache unterscheidet sich von den natürlichen (National-)Sprachen der menschlichen Kommunikation und des Denkens, von künstlichen Sprachen wie Esperanto, von den „technischen“ Sprachen der Wissenschaft, die die Mittel eines bestimmten Teils des Natürlichen vereinen Sprache mit den entsprechenden wissenschaftlichen Symbolen (die Sprache der Chemie, die Sprache der gewöhnlichen Mathematik usw.), aus algorithmische Sprache generischer Programmiertyp usw. vor allem dadurch, dass seine Aufgabe darin besteht, als Mittel zur Fixierung (Formalisierung) eines bestimmten logischen Inhalts zu dienen, was die Einführung der Beziehung der logischen Konsequenz und des Konzepts der Beweisbarkeit (oder ihrer Analoga) ermöglicht. Historisch gesehen war die erste formalisierte Sprache syllogistisch Aristoteles, implementiert unter Verwendung eines standardisierten natürlichen (griechischen) Sprachfragments. Die allgemeine Idee einer formalisierten Sprache wurde von Leibniz (characteristica universalis) formuliert, der für ihre Erweiterung auf den "Kalkül der Inferenzen" - calculus ratiocinator - sorgte. In der neuen Zeit Verschiedene Optionen Formalisierte Sprachen wurden auf der Grundlage der Analogie zwischen Logik und Algebra entwickelt. Der Meilenstein hier war die Arbeit Morgana , Bool und ihre Anhänger, besonders Schröder und Poretzki . Moderne formalisierte Sprachen – in ihren gebräuchlichsten Formen – gehen auf die Arbeit zurück. Frege „Begriffsschrift“ (1879), aus der die Hauptentwicklungslinie der Sprache der Aussagenlogik und (sie umfassend) der Logik der (Mehrfach-)Prädikate sowie der Anwendung dieser logischen Sprachmittel hervorgeht zu den Problemen der mathematischen Begründung.
Der charakteristische Aufbau solcher formalisierter Sprachen: die Zuordnung des Alphabets von Anfangszeichen, die induktive Definition einer (wohlgeformten) Formel der Sprache, der sog. das Festlegen der Bildungsregeln, das Festlegen der Schlußregeln, die sogenannten. Transformationsregeln, die die gewählte logische Eigenschaft von Formeln bewahren (Wahrheit, Beweisbarkeit etc.). Das Hinzufügen von Transformationsregeln verwandelt die formalisierte Sprache in ein logisches Kalkül. Es gibt viele Arten von formalisierten Sprachen: Dies sind vor allem Sprachen deduktiv-axiomatischer Konstruktionen, Systeme natürlicher ("natürlicher") Schlussfolgerungen und sequentieller Konstruktionen, analytische Tabellen, "Argumentlogik" -Systeme und viele andere.
Formalisierte Sprachen unterscheiden sich in ihrer logischen Stärke von „klassischen“ Sprachen (in denen die aristotelischen Gesetze der Identität, des Widerspruchs und des ausgeschlossenen Dritten sowie des Prinzips der logischen Mehrdeutigkeit in vollem Umfang gelten) und enden mit zahlreichen Sprachen von nicht-klassischen Logiken, die es ermöglichen, bestimmte Prinzipien zu schwächen, Polysemie der Bewertung von Formeln oder ihrer Modalitäten einzuführen. Es wurden Sprachen entwickelt, in denen logische Mittel auf die eine oder andere Weise minimiert werden. Das sind zum Beispiel die Sprachen der minimalen und positiven Logik oder die Sprache der Aussagenlogik, die eine einzige logische Operation verwendet. Schaeffers Schlaganfall (vgl Logische Verknüpfungen ).
Formalisierte Sprachen werden in der Regel syntaktisch und semantisch charakterisiert. Das Wesentlichste aber ist jener logische Charakter seiner Formeln, der durch die Schlußregeln (Wahrheit, Beweisbarkeit, Verifizierbarkeit, Wahrscheinlichkeit usw.) bewahrt wird. Für jede formalisierte Sprache sind die grundlegenden Probleme die Vollständigkeit der darin ausgedrückten Logik, ihre Entscheidbarkeit und Konsistenz; zB die Sprache der Klassik Aussagelogik vollständig, auflösbar und konsistent und klassisch Prädikatenlogik (mehrfach) zwar vollständig, aber unlösbar; die Sprache des erweiterten Prädikatenkalküls – mit Quantoren durch Prädikate und unbegrenzter Anwendung des Abstraktionsprinzips – ist widersprüchlich (so war Freges logisch-arithmetisches System, in dem Russell die nach ihm benannte Antinomie entdeckte).
Eine formalisierte Sprache kann eine "reine Form" sein, d.h. keine extralogischen Informationen enthalten; wenn es sie trägt, dann wird es zu einer angewandten formalisierten Sprache, deren Besonderheit das Vorhandensein konstanter Prädikate und Begriffe (Beschreibungen) ist - zum Beispiel. Arithmetik - die Eigenschaften des Anwendungsbereichs widerspiegelt. Um Theorien mit hohem Abstraktionsniveau zu formalisieren, kann eine formalisierte Sprache auf verschiedene Weise modifiziert, erweitert oder "aufgebaut" werden; Beispiel: Formalisierung der klassischen Analysis als Arithmetik zweiter Ordnung (dh mit Quantoren über Prädikatsvariablen). In einer Reihe von Fällen enthält eine formalisierte Sprache logische Strukturen vieler – sogar unendlich vieler – Ordnungen (wie z einer Hierarchie „möglicher Welten“). Die semantische Basis einer formalisierten Logiksprache kann mengentheoretisch, algebraisch, probabilistisch, spieltheoretisch usw. sein. Es kann auch solche „Schwächungen“ davon geben, die nur der probabilistischen Semantik verwandt sind – so z. es entsteht eine formalisierte Sprache der „vagen Logik“ (im Sinne von Zade). Dann erhält die Sprache eine spezifische Pragmatik, die den Faktor des Muttersprachlers berücksichtigt (was eine Einschätzung der „Zugehörigkeitsfunktion“ des Subjekts zum Geltungsbereich dieses Konzepts gibt). Hier manifestiert sich die jetzt wachsende Tendenz, den „Faktor Mensch“ in formalisierten Sprachen in der einen oder anderen Form zu berücksichtigen, was sich in einigen formalisierten Sprachen der Logik der Quantenmechanik deutlich manifestiert. In eine andere Richtung geht es um die Entwicklung formalisierter Sprachen, deren Semantik die Ablehnung existenzieller Annahmen oder bestimmter ontologischer Prämissen impliziert - über die Zulässigkeit von Regeln mit unendlich vielen Prämissen, "multi-sort" Themenbereiche, auch widersprüchliche usw.
Ein unverzichtbares Merkmal einer formalisierten Sprache ist die "Möglichkeits"-Interpretation der Schlußregeln; zum Beispiel steht es uns frei, in einem bestimmten Schritt, sagen wir, die Modus-Ponens-Regel zu verwenden oder nicht zu verwenden. Diese Eigenschaft wird algorithmischen Sprachen vorenthalten, die einen „präskriptiven“ Charakter haben. Aber mit der Entwicklung der Computerlogik und der Entwicklung von Programmen des "beschreibenden" Typs beginnt sich dieser Unterschied auszugleichen. In die gleiche Richtung geht auch die Entwicklung formalisierter Sprachen, die sich auf die Lösung heuristischer Probleme konzentrieren.
Literatur:
1. Kirche A. Einführung in die mathematische Logik, Bd. 1. M., 1960;
2. Kleene S.K. Einführung in die Metamathematik. M, 1957;
3. Curry H. Grundlagen der mathematischen Logik. M, 1969;
4. Freudenthal H. Die Sprache der Logik. M, 1969;
5. Smirnova E.D. Formalisierte Sprachen und Probleme der logischen Semantik. M., 1982.
In den vergangenen 70 Jahren hat sich die Programmierung zu einem riesigen Bereich menschlicher Tätigkeit entwickelt, dessen Ergebnisse in ihrer praktischen Bedeutung durchaus mit den neuesten Ergebnissen auf dem Gebiet der Kernphysik oder der Weltraumforschung vergleichbar sind. Diese Ergebnisse hängen weitgehend mit der Entstehung und schnellen Entwicklung von höheren algorithmischen Sprachen zusammen.
Moderne höhere Programmiersprachen wie Pascal, C, Ada, Java, C++, C# und andere sind nach wie vor das gängigste und leistungsfähigste Werkzeug für Programmierer, die an der Entwicklung von System- und Anwendungssoftware beteiligt sind. Mit dem Aufkommen neuer Aufgaben und Bedürfnisse wird die Funktionalität dieser Sprachen ständig erweitert, indem immer fortschrittlichere Versionen erstellt werden.
Eine andere Richtung in der Entwicklung von Programmiersprachen ist mit der Erstellung spezialisierter (problemorientierter) Softwaresysteme und -umgebungen für Nicht-Programmierer (Technologen, Designer, Wirtschaftswissenschaftler usw.) verbunden. Beispiele für solche Systeme und Umgebungen sind CAD für verschiedene Zwecke, automatisierte Lernsysteme, Fernlernsysteme, Experten- und Modellierungssysteme in der Wirtschaft usw. Der Zweck der entsprechenden problemorientierten Sprachen, die in solchen Systemen verwendet werden, spiegelt sich häufig in ihren Namen wider, z. , etc.
Sowohl universelle als auch domänenspezifische Programmiersprachen haben eines gemeinsam – sie sind es
formale Sprachen. Was ist eine formale Sprache? In der sehr Gesamtansicht Diese Frage lässt sich so beantworten: Sprache - Es sind viele Vorschläge formelle Sprache - es ist eine Sprache, deren Sätze nach bestimmten Regeln aufgebaut sind.
Sätze werden aus Wörtern gebildet, und Wörter werden aus Symbolen (Buchstaben) gebildet. Die Menge aller zulässigen Symbole wird aufgerufen alphabetisch Sprache. In Programmiersprachen entsprechen Sätze normalerweise Operatoren (oder Anweisungen), und wir sehen alphabetische Zeichen auf einer Computertastatur.
Sowohl natürliche Sprachen als auch Programmiersprachen sind unendliche Mengen. In einer Programmiersprache kann eine unbegrenzte Anzahl von Programmen geschrieben werden.
Wie stellt man die Regeln für den Satzbau in einer formalen Sprache auf? Bei der Beantwortung dieser Frage gehen wir von zwei wichtigen Konzepten aus: Syntax und Semantik Sprache.
Syntax Sprache bestimmt den Aufbau korrekter Sätze und Wörter, in Programmiersprachen unter anderem die zulässigen Strukturen von Programmtexten.
Existiert verschiedene Wege Beschreibungen der Syntax formaler Sprachen (das zweite Kapitel des Lehrbuchs ist Beschreibungsmethoden gewidmet). Die am häufigsten verwendeten Programmiersprachen sind Backus-Form - Naura(BNF) und Syntaxdiagramme.
Die BNF wurde von Backus entwickelt und erstmals 1963 für eine strenge Beschreibung der ALGOL-60-Sprache verwendet. Diese Form wird sowohl zur Beschreibung der Struktur der Sprache als Ganzes als auch zur Beschreibung einzelner Sprachkonstrukte (Teilmengen der Sprache) verwendet. und seine Elemente - Operatoren, Bezeichner, Ausdrücke, Zahlen usw.
Im Folgenden finden Sie BNF-Beispiele, die die Syntax für Dezimalzahlen und die Syntax für arithmetische Ausdrücke mit den Operatoren „+“ und „*“ definieren.
BNF-Dezimalzahlen:
= 0|1|...|9
BNF arithmetischer Ausdrücke:
:= () a
In den obigen Ausdrücken a steht für einen beliebigen Bezeichner und wird als Zeichen des Alphabets behandelt, aus dem der Ausdruck aufgebaut ist.
Auf der linken Seite der BNF werden die Namen der definierten Parameter in spitzen Klammern geschrieben. syntaktische Kategorien(Begriffe, Einheiten), das Symbol „:=“ bedeutet „ist“, „dies“, „ist definiert als“, das Symbol „|“ bedeutet „oder“.
Der rechte Teil der BNF definiert mögliche Optionen zur Konstruktion bestimmter Werte dieser Kategorien, in diesem Fall der Werte Dezimal Zahlen und spezifische arithmetische Ausdrücke. Die BNF enthält auch das Alphabet der Zeichen, aus denen sich diese Werte zusammensetzen. Bei Dezimalzahlen ist das Alphabet die Menge (+,-, 0, 1,..., 9) und bei Ausdrücken die Menge (a, *, +, (,)}.
Der Prozess der Konstruktion der Bedeutungen einer syntaktischen Kategorie besteht aus Rückzug diese Werte durch sukzessive Substitutionen der rechten Teile der BNF-Regeln in die linken. Das Folgende sind die Ableitungen der Zahl "-320" und des Ausdrucks "a+a*a"über die entsprechende BNF:
BNF sind sehr ähnlich formale Grammatiken in der Theorie der formalen Sprachen verwendet (einige Autoren identifizieren sie).
Es war das Erscheinen des BNF, das die rasche Entwicklung der Theorie der formalen Sprachen und ihre Anwendung auf angewandte Probleme der Entwicklung von Programmiersprachen und des Entwurfs von Übersetzern anregte.
Wenn in der betrachteten BNF jede syntaktische Kategorie von der linken Seite der Regeln mit bezeichnet wird A, B und Mit bzw. und anstelle des Symbols:= use -dann werden die folgenden Formen erhalten:
Für Dezimalzahlen:
A->B+B-B B^>CBC C->0 | 11... | neun
Für arithmetische Ausdrücke:
A^A+BB
B->B*SS
C^>(A)a
So sind die Regeln geschrieben formale Grammatiken. Symbole, die syntaktische Kategorien bezeichnen, in diesem Fall, B, C in formalen Grammatiken genannt werden nichtterminale Symbole und die Buchstaben des Alphabets sind Terminal.
In der Praxis ist es nach dem Erwerb der Grammatik einer Programmiersprache in „erster Näherung“ notwendig, ihre Eigenschaften zu untersuchen und gegebenenfalls einige Transformationen vorzunehmen. Dies liegt hauptsächlich an der Notwendigkeit, die Grammatik in eine geeignete Form zu bringen, um den entsprechenden Übersetzer zu konstruieren. Bei der Durchführung dieser Transformationen spielt es aus formaler Sicht keine Rolle, welche spezifischen syntaktischen Kategorien und Symbole des Alphabets BNF enthalten sind. Daher geht man an dieser Stelle meist zur formalen Grammatik über und wendet die entsprechenden Methoden der Theorie der formalen Sprachen an. Gleichzeitig sollte BNF nicht vollständig mit formalen Grammatiken identifiziert werden. Die Definition der Grammatik in der Theorie der formalen Sprachen ist allgemeiner. Sie können insbesondere zur Beschreibung verwendet werden Kontextabhängigkeiten, die sich bei der Entwicklung von Programmiersprachen nicht immer vermeiden lassen und die sich nicht mit BNF beschreiben lassen.
Ein charakteristisches Merkmal der Grammatiken von Programmiersprachen ist das Vorhandensein von Rekursion in ihnen. Rekursivität bedeutet, dass die Definition einer syntaktischen Kategorie die definierte Kategorie selbst enthält (dies ist die sogenannte explizite Rekursion). Zum Beispiel in der betrachteten BNF die Definitionen für die Kategorien und enthalten diese Kategorien selbst auf der rechten Seite. Rekursion - eine fast unvermeidliche Eigenschaft der Grammatiken von Programmiersprachen, die es ermöglicht, sie unendlich zu machen. Gleichzeitig erschweren einige Rekursionsarten, auf die später eingegangen wird, den Prozess der Entwicklung der entsprechenden Übersetzer erheblich.
Lassen Sie uns kurz auf eine andere Möglichkeit eingehen, die Syntax einer Sprache, die oben erwähnt wurde, mit Hilfe von Syntaxdiagrammen zu beschreiben. Einige Autoren bevorzugen bei der Beschreibung des Sprachstandards diese Methode aufgrund der größeren Übersichtlichkeit. Beispiele für Syntaxdiagramme finden sich in vielen Programmierbüchern (z. B. in ). Beachten Sie, dass beide Beschreibungsmethoden – sowohl BNF als auch syntaktische Diagramme – gleichwertig sind und Sie jederzeit von einer Beschreibungsmethode zur anderen wechseln können.
Betrachten Sie nun das Konzept die Semantik der Sprache. Wenn die Syntax einer Sprache die Struktur ihrer korrekten Sätze und Texte bestimmt, dann bestimmt die Semantik die Korrektheit ihrer Bedeutung. Die Richtigkeit der Bedeutung hängt wiederum von der Bedeutung der Wörter ab, aus denen der Satz besteht. Wenn zum Beispiel in natürlicher Sprache die Satzsyntax definiert ist als
Dann können Sie eine Reihe von Sätzen mit unterschiedlichen Bedeutungen bilden. Beispielsweise sind die Sätze „Auto fährt“ und „Auto denkt“ syntaktisch korrekt. Der erste Satz hat jedoch die richtige Bedeutung, der zweite kann als bedeutungslos bezeichnet werden. Die Semantik bestimmt also die Menge der Bedeutungen und zulässigen Korrespondenzen zwischen Sätzen (Texten) und Bedeutungen.
Außerdem hängt die Semantik einer Sprache von den Eigenschaften der in dieser Sprache beschriebenen Objekte ab. Wenn das Auto im betrachteten Beispiel mit einem Computer mit Programmen zur Berechnung der optimalen Bewegungsarten und -routen ausgestattet wäre, dann würde der zweite Satz nicht mehr sinnlos erscheinen.
Ebenso in Programmiersprachen der syntaktisch wohlgeformte Zuweisungsoperator
ist semantisch falsch, wenn a 10,5 ist (a = 10,5) und b falsch ist (b = false).
Die formale Beschreibung der Semantik von Programmiersprachen stellte sich als deutlich schwieriger heraus als die Beschreibung der Syntax. Die meisten Arbeiten, die sich der Anwendung mathematischer Methoden bei der Implementierung von Programmiersprachen widmen, behandeln genau die Probleme der Beschreibung der Syntax und der Konstruktion von Parsing-Methoden. Auf diesem Gebiet hat sich eine ziemlich ganzheitliche Theorie und Methodik entwickelt. Gleichzeitig sind Sprachsemantik und semantische Analyse immer noch Gegenstand vieler Studien.
Viele Aspekte der Semantik einer Programmiersprache lassen sich als eine Liste von semantischen Konventionen beschreiben, die allgemeiner, informeller Natur sind. Programmierer sind zum Beispiel mit Konventionen wie „jeder Bezeichner in einem Block wird einmal deklariert“, „eine Variable muss definiert werden, bevor sie verwendet werden kann“ usw. vertraut.
Als Beispiel für die erfolgreiche Anwendung der Theorie der formalen Sprachen im Bereich der Semantik und semantischen Analyse kann man den Apparat der attributiven Übersetzungsgrammatik anführen, der es erlaubt, semantische Übereinstimmungen bei der Beschreibung einer Sprache zu berücksichtigen und zu berücksichtigen ihre Einhaltung während der Programmübersetzung kontrollieren.
Was die Prognosen für die Perspektiven der Weiterentwicklung von Programmiersprachen betrifft, so gibt es eine ziemlich breite Palette von Meinungen, bis hin zu diametral entgegengesetzten. Einige Autoren glauben, dass jede der Sprachen ihre eigenen semantischen Merkmale hat, die sie für einen bestimmten Bereich der Programmierung bequem und attraktiv machen (z. B. konzentrieren sich Prolog und Lisp auf die Lösung von Problemen der künstlichen Intelligenz; Fortran ist am effektivsten). Lösen von Berechnungsproblemen; Cobol - wird für wirtschaftliche Berechnungen usw. verwendet). Daher sollten Sie alle neuen Sprachen mit bestimmten Funktionen erstellen oder vorhandene Versionen regelmäßig aktualisieren und nicht versuchen, eine universelle Sprache zu erstellen. Zur Stützung dieser Sichtweise wird argumentiert, dass alle ehrgeizigen Projekte zur Schaffung einer universellen Sprache gescheitert sind (es genügt, an die unerfüllten Hoffnungen zu erinnern, die mit der Entwicklung von ADAiPL-1-Sprachen verbunden sind).
Ein anderer Teil der Autoren glaubt, dass seit der Veröffentlichung der Standards der ersten Programmiersprachen - Fortran, Algol usw. - in den 60er Jahren. Jahrhunderts kam es zu einer „Stabilisierung“ von Sprachen in dem Sinne, dass Sprachkonstruktionen mit ähnlichem Zweck in verschiedene Sprachen haben fast die gleiche semantische Basis, trotz Unterschieden in Vokabular und Syntax. Sobald es also möglich ist, diese gemeinsame semantische Basis formal zu definieren, wird es möglich sein, mit der Schaffung einer universellen Sprache zu beginnen, die keine Programmiersprache im traditionellen Sinne mehr sein wird, sondern Leerzeichen semantischer Strukturen. Das Programm wird als eine Menge dieser Konstrukte präsentiert, und der Texteditor weicht dem Struktureditor. Als Beispiel für eine teilweise Umsetzung dieses Ansatzes seien visuelle Programmierumgebungen wie Delphi, C++ Builder etc. genannt.
Ende
Start
Wiederholen
Start
Pseudo-Codes
Pseudocode ist ein System aus Notationen und Regeln, das entwickelt wurde, um Algorithmen einheitlich zu schreiben. Sie nimmt eine Zwischenstellung zwischen natürlicher und formaler Sprache ein.
Einerseits ist es der gewöhnlichen natürlichen Sprache nahe, sodass Algorithmen darin wie einfacher Text geschrieben und gelesen werden können. Andererseits werden einige formale Konstruktionen und mathematische Symbolik im Pseudocode verwendet, was die Notation des Algorithmus näher an die allgemein akzeptierte mathematische Notation bringt.
Pseudocode übernimmt keine strengen syntaktischen Regeln zum Schreiben von Befehlen, die formalen Sprachen inhärent sind, was das Schreiben eines Algorithmus in der Entwurfsphase erleichtert und es ermöglicht, einen breiteren Satz von Befehlen zu verwenden, die für einen abstrakten Ausführenden entwickelt wurden. In Pseudocode gibt es jedoch normalerweise einige Konstrukte, die formalen Sprachen inhärent sind, was den Übergang vom Schreiben in Pseudocode zum Schreiben eines Algorithmus in einer formalen Sprache erleichtert. Insbesondere im Pseudocode sowie in formalen Sprachen gibt es Hilfswörter, deren Bedeutung ein für alle Mal festgelegt ist. Sie sind in gedrucktem Text fett gedruckt und in handschriftlichem Text unterstrichen. Es gibt keine einheitliche oder formale Definition von Pseudocode, daher sind verschiedene Pseudocodes möglich, die sich in der Menge der Dienstwörter und grundlegenden (Grund-)Strukturen unterscheiden. Als Beispiel geben wir einen Eintrag zu einem der Pseudocodes des Algorithmus:
Algorithmus Euklids Algorithmus;
Tschüss die erste Zahl ist nicht gleich der zweiten
wenn die Zahlen sind gleich
dann halt Alle;
Andernfalls die größere von zwei Zahlen bestimmen;
hÄndern Sie die größere Zahl in die Differenz zwischen der größeren und der kleineren Zahl
das Ende;
Nehmen Sie die erste Zahl als Antwort
Dieser Algorithmus kann auf einfachere Weise geschrieben werden, aber eine solche Notation wird gegeben, um die wichtigsten möglichen Pseudocode-Konstruktionen zu demonstrieren. Aufgrund ihrer Besonderheiten sind Pseudocodes, wie die anderen oben beschriebenen Mittel zum Schreiben von Algorithmen, menschenorientiert.
Oben wurde angemerkt, dass beim Schreiben eines Algorithmus in verbaler Form, in Form eines Diagramms oder in Pseudocode eine gewisse Willkür bei der Anzeige von Befehlen zulässig ist. Gleichzeitig ist eine solche Aufzeichnung so genau, dass sie es einer Person ermöglicht, das Wesentliche der Angelegenheit zu verstehen und den Algorithmus auszuführen.
In der Praxis werden jedoch spezielle Automaten - elektronische Rechner (Computer) - als Ausführende von Algorithmen verwendet. Daher muss ein für die Ausführung auf einem Computer vorgesehener Algorithmus in einer für den Computer "verständlichen" Sprache geschrieben sein. Und hier tritt die Notwendigkeit einer genauen Aufzeichnung von Befehlen in den Vordergrund, die keinen Raum für willkürliche Interpretationen durch ihren Ausführenden lässt. Daher muss die Sprache zum Schreiben des Algorithmus formalisiert werden. Eine solche Sprache heißt Programmiersprache , und die Aufzeichnung des Algorithmus in dieser Sprache ist Programm für Rechner.
Programmiersprache ist eine formalisierte Sprache, die eine Kombination aus dem Alphabet, den Regeln zum Schreiben von Konstruktionen (Syntax) und den Regeln zum Interpretieren von Konstruktionen (Semantik) ist.
Derzeit gibt es mehrere hundert Programmiersprachen, die für verschiedene Anwendungsbereiche von Computern konzipiert sind, dh für verschiedene Klassen von Aufgaben, die mit Hilfe von Computern gelöst werden. Diese Sprachen werden nach klassifiziert verschiedene Level, wobei der Grad der Abhängigkeit der Sprache von einem bestimmten Computer berücksichtigt wird.
Von Zeit zu Zeit erscheinen Beiträge und übersetzte Artikel auf Habré, die sich bestimmten Aspekten der Theorie formaler Sprachen widmen. Unter solchen Veröffentlichungen (ich möchte nicht auf bestimmte Arbeiten hinweisen, um ihre Autoren nicht zu beleidigen), insbesondere unter denjenigen, die sich der Beschreibung verschiedener Softwaretools zur Sprachverarbeitung widmen, gibt es oft Ungenauigkeiten und Verwirrung. Der Autor neigt zu der Annahme, dass einer der Hauptgründe für diesen unglücklichen Zustand das unzureichende Verständnis der Ideen ist, die der Theorie der formalen Sprachen zugrunde liegen.Dieser Text ist als populäre Einführung in die Theorie der formalen Sprachen und Grammatiken gedacht. Diese Theorie gilt (und ich muss sagen, zu Recht) als ziemlich komplex und verwirrend. Studenten langweilen sich in der Regel in Vorlesungen, und Prüfungen wecken zudem keine Begeisterung. Daher gibt es in der Wissenschaft nicht so viele Forscher auf diesem Gebiet. Es genügt zu sagen, dass seit der Geburt der Theorie der formalen Grammatiken Mitte der 50er Jahre des letzten Jahrhunderts bis heute nur zwei Dissertationen in dieser wissenschaftlichen Richtung veröffentlicht wurden. Einer von ihnen wurde Ende der 60er Jahre von Alexei Vladimirovich Gladkiy geschrieben, der zweite steht bereits an der Schwelle des neuen Jahrtausends - von Mati Pentus.
Darüber hinaus werden in der zugänglichsten Form zwei grundlegende Konzepte der Theorie der formalen Sprachen beschrieben: formale Sprache und formale Grammatik. Wenn der Test für das Publikum interessant ist, verspricht der Autor feierlich, ein paar weitere ähnliche Werke hervorzubringen.
Formale Sprachen
Kurz gesagt, eine formale Sprache ist ein mathematisches Modell einer realen Sprache. Reale Sprache wird hier als eine bestimmte Art der Kommunikation (Kommunikation) von Subjekten untereinander verstanden. Zur Kommunikation verwenden Subjekte eine endliche Menge von Zeichen (Symbolen), die in einer strikten zeitlichen Reihenfolge ausgesprochen (ausgeschrieben) werden, d.h. lineare Folgen bilden. Solche Sequenzen werden normalerweise Wörter oder Sätze genannt. Also nur die sog. kommunikative Funktion der Sprache, die mit mathematischen Methoden untersucht wird. Andere Funktionen der Sprache werden hier nicht untersucht und daher nicht berücksichtigt.Um besser zu verstehen, wie formale Sprachen gelernt werden, ist es zunächst notwendig, die Merkmale mathematischer Lernmethoden zu verstehen. Laut Kolmogorov et al. (Aleksandrov A.D., Kolmogorov A.N., Lavrentiev M.A. Mathematik. Inhalt, Methoden und Bedeutung. Band 1. M .: Verlag der Akademie der Wissenschaften der UdSSR, 1956.), mathematische Methode, zu was auch immer angewendet wird, folgt sie immer zwei Grundprinzipien:
- Verallgemeinerung (Abstraktion). Mathematische Studienobjekte sind spezielle Entitäten, die nur in der Mathematik existieren und von Mathematikern untersucht werden sollen. Mathematische Objekte werden durch Verallgemeinerung realer Objekte gebildet. Beim Studium eines Objekts bemerkt der Mathematiker nur einige seiner Eigenschaften und wird vom Rest abgelenkt. Das abstrakte mathematische Objekt „Zahl“ kann also tatsächlich die Anzahl der Gänse in einem Teich oder die Anzahl der Moleküle in einem Wassertropfen bedeuten; Hauptsache man kann über Gänse und Wassermoleküle sprechen
über Aggregate sprechen. Eine wichtige Eigenschaft folgt aus einer solchen „Idealisierung“ realer Objekte: Die Mathematik arbeitet oft mit unendlichen Sammlungen, während solche Sammlungen in Wirklichkeit gar nicht existieren. - Rigidität der Argumentation. In der Wissenschaft ist es üblich, die Richtigkeit der einen oder anderen Argumentation zu überprüfen, indem man ihre Ergebnisse mit dem vergleicht, was tatsächlich existiert, d.h. Experimente durchführen. In der Mathematik funktioniert dieses Kriterium zur Überprüfung der logischen Argumentation nicht. Daher werden die Schlussfolgerungen nicht experimentell verifiziert, aber es ist üblich, ihre Gültigkeit durch strenge Argumentation zu beweisen, die bestimmten Regeln gehorcht. Diese Argumente werden Beweise genannt, und Beweise dienen als einzige Möglichkeit, die Richtigkeit einer bestimmten Aussage zu untermauern.
Als berühmtes Beispiel Eine solche mathematische Abstraktion kann als Modell zitiert werden, das unter dem für das russische Ohr dissonanten Namen „Worttüte“ bekannt ist. In diesem Modell werden Texte in natürlicher Sprache (dh eine der Sprachen, die Menschen im Prozess der alltäglichen Kommunikation miteinander verwenden) untersucht. Das Hauptobjekt des Bag-of-Words-Modells ist ein Wort, das mit einem einzigen Attribut ausgestattet ist, der Häufigkeit des Vorkommens dieses Wortes im Ausgangstext. Das Modell berücksichtigt nicht, wie Wörter nebeneinander platziert werden, sondern nur, wie oft jedes Wort im Text vorkommt. Die Worttüte wird beim textbasierten maschinellen Lernen als eines der Hauptstudienobjekte verwendet.
Aber in der Theorie der formalen Sprachen scheint es wichtig zu sein, die Gesetze der Anordnung von Wörtern nebeneinander zu studieren, d.h. syntaktische Eigenschaften von Texten. Dafür sieht das Bag of Words-Modell schlecht aus. Daher ist eine formale Sprache als eine Menge von Folgen definiert, die aus Elementen eines endlichen Alphabets bestehen. Lassen Sie uns dies strenger definieren.
Das Alphabet ist eine endliche, nicht leere Menge von Elementen. Diese Elemente werden Symbole genannt. Um das Alphabet zu bezeichnen, verwenden wir normalerweise das lateinische V, und um die Symbole des Alphabets zu bezeichnen, verwenden wir die ersten Kleinbuchstaben des lateinischen Alphabets. Beispielsweise bezeichnet der Ausdruck V = (a,b) ein Alphabet aus zwei Zeichen a und b.
Ein String ist eine endliche Folge von Zeichen. Beispielsweise ist abc eine Zeichenfolge aus drei Zeichen. Bei der Bezeichnung von Ketten in Symbolen werden häufig Indizes verwendet. Die Ketten selbst werden durch Kleinbuchstaben am Ende des griechischen Alphabets bezeichnet. Beispielsweise ist omega = a1...an eine Zeichenfolge aus n Zeichen. Die Kette kann leer sein, d.h. kein Zeichen enthalten. Solche Ketten werden mit dem griechischen Buchstaben Epsilon bezeichnet.
Schließlich ist eine formale Sprache L über einem Alphabet V eine beliebige Menge von Zeichenketten, die aus Zeichen des Alphabets V zusammengesetzt sind. Willkür bedeutet hier, dass die Sprache leer sein kann, d.h. keine einzige Kette haben und unendlich, d.h. bestehend aus unendlich vielen Ketten. Der letzte Fakt ist oft rätselhaft: Gibt es echte Sprachen, die unendlich viele Zeichenketten enthalten? Generell ist alles in der Natur endlich. Aber hier verwenden wir die Unendlichkeit als Möglichkeit, Ketten von unbegrenzter Länge zu bilden. Beispielsweise ist eine Sprache, die aus den möglichen Variablennamen der Programmiersprache C++ besteht, unendlich. Schließlich sind Variablennamen in C++ nicht in der Länge begrenzt, sodass es potenziell unendlich viele solcher Namen geben kann. In Wirklichkeit ergeben uns natürlich lange Variablennamen wenig Sinn. Am Ende des Lesens eines solchen Namens vergisst man bereits seinen Anfang. Aber als mögliche Möglichkeit, Variablen unbegrenzter Länge zu setzen, sieht diese Eigenschaft nützlich aus.
Formale Sprachen sind also einfach Sätze von Zeichenfolgen, die aus Symbolen eines endlichen Alphabets bestehen. Aber es stellt sich die Frage: Wie kann man eine formale Sprache definieren? Wenn die Sprache endlich ist, dann kann man einfach alle ihre Ketten nacheinander aufschreiben (natürlich könnte man sich fragen, ob es sinnvoll ist, die Ketten einer Sprache aufzuschreiben, die mindestens zehntausend Elemente hat, und im Allgemeinen macht es Sinn, so etwas aufzuschreiben?). Was tun, wenn die Sprache unendlich ist, wie definiert man sie? Hier kommt die Grammatik ins Spiel.
Formale Grammatiken
Die Art, eine Sprache zu spezifizieren, wird als Grammatik dieser Sprache bezeichnet. Daher nennen wir Grammatik jede Art, eine Sprache zu spezifizieren. Beispielsweise definiert die Grammatik L = (a^nb^n) (hier ist n eine natürliche Zahl) eine Sprache L, die aus Zeichenketten der Form ab, aabb, aaabbb usw. besteht. Die Sprache L ist eine unendliche Menge von Strings, aber trotzdem besteht ihre Grammatik (Beschreibung) nur aus 10 Zeichen, d.h. endlich.Der Zweck der Grammatik ist die Aufgabe der Sprache. Diese Aufgabe muss unbedingt endgültig sein, sonst wird die Person diese Grammatik nicht verstehen können. Aber wie beschreibt die letzte Aufgabe unendliche Sammlungen? Dies ist nur möglich, wenn die Struktur aller Ketten der Sprache auf einheitlichen Prinzipien beruht, von denen es eine endliche Anzahl gibt. Im obigen Beispiel fungiert das folgende Prinzip als ein solches Prinzip: "Jeder String der Sprache beginnt mit den Zeichen a, gefolgt von der gleichen Anzahl von Zeichen b". Wenn eine Sprache eine unendliche Ansammlung zufällig typisierter Ketten ist, deren Struktur keinen einheitlichen Prinzipien gehorcht, dann ist es offensichtlich unmöglich, eine Grammatik für eine solche Sprache zu erfinden. Und hier ist eine andere Frage, ob eine solche Sammlung als Sprache betrachtet werden kann oder nicht. Aus Gründen der mathematischen Strenge und Einheitlichkeit des Ansatzes werden solche Sammlungen normalerweise als Sprache betrachtet.
Die Grammatik einer Sprache beschreibt also die Gesetze der inneren Struktur ihrer Ketten. Solche Gesetze werden üblicherweise als syntaktische Gesetze bezeichnet. Daher kann man die Definition von Grammatik als die endgültige Art der Beschreibung der syntaktischen Muster einer Sprache umformulieren. Für die Praxis sind nicht nur Grammatiken interessant, sondern Grammatiken, die im Rahmen eines einzigen Ansatzes (Formalismus oder Paradigma) gesetzt werden können. Also auf der Grundlage einer einzigen Sprache (Metasprache) zur Beschreibung der Grammatiken aller formalen Sprachen. Dann können Sie einen Algorithmus für einen Computer entwickeln, der eine Beschreibung der in dieser Metasprache erstellten Grammatik als Eingabe nimmt und etwas mit den Ketten der Sprache macht.
Solche Paradigmen zur Beschreibung von Grammatiken werden syntaktische Theorien genannt. Formale Grammatik ist ein mathematisches Modell der Grammatik, das im Rahmen einer Art syntaktischer Theorie beschrieben wird. Es gibt einige solcher Theorien. Die bekannteste Metasprache zur Spezifizierung von Grammatiken ist natürlich Chomskys generative Grammatiken. Aber es gibt auch andere Formalismen. Eine davon, Nachbarschaftsgrammatiken, wird unten beschrieben.
Aus algorithmischer Sicht lassen sich Grammatiken nach der Art der Sprachangabe unterteilen. Es gibt drei Hauptwege (Arten von Grammatiken):
- Grammatiken erkennen. Solche Grammatiken sind Geräte (Algorithmen), denen als Eingabe eine Sprachkette gegeben wird, und am Ausgang gibt das Gerät „Ja“ aus, wenn die Kette zu der Sprache gehört, andernfalls „Nein“.
- Grammatiken generieren. Diese Art von Gerät wird verwendet, um Sprachketten nach Bedarf zu generieren. Bildlich gesprochen wird beim Drücken einer Taste eine Sprachkette generiert.
- Enumerative Grammatiken. Solche Grammatiken drucken nacheinander alle Ketten der Sprache. Wenn eine Sprache aus einer unendlichen Anzahl von Zeichenketten besteht, dann wird der Aufzählungsprozess offensichtlich niemals aufhören. Allerdings kann er natürlich zum richtigen Zeitpunkt zwangsweise angehalten werden, wenn zum Beispiel die gewünschte Kette gedruckt ist.
Nachbarschaftsgrammatiken
Mitte der 60er Jahre schlug der sowjetische Mathematiker Yuliy Anatolyevich Shreider einen einfachen Weg vor, um die Syntax von Sprachen auf der Grundlage des sogenannten zu beschreiben. Nachbarschaftsgrammatiken. Für jedes Zeichen der Sprache wird eine endliche Anzahl seiner „Nachbarschaften“ angegeben – Ketten, die dieses Zeichen (das Zentrum der Nachbarschaft) irgendwo darin enthalten. Eine Menge solcher Nachbarschaften für jedes Zeichen des Alphabets einer Sprache wird als Nachbarschaftsgrammatik bezeichnet. Eine Kette wird als zu der durch die Nachbarschaftsgrammatik definierten Sprache gehörend angesehen, wenn jedes Symbol dieser Kette zusammen mit einem Teil ihrer Nachbarschaft darin enthalten ist.Betrachten Sie als Beispiel die Sprache A = (a+a, a+a+a, a+a+a+a,...) . Diese Sprache ist das einfachste Modell der Sprache arithmetischer Ausdrücke, bei der das Symbol "a" die Rolle von Zahlen und das Symbol "+" die Rolle von Operationen spielt. Lassen Sie uns eine Nachbarschaftsgrammatik für diese Sprache verfassen. Legen wir die Nachbarschaft für das Symbol "a" fest. Das Zeichen „a“ kann in Zeichenfolgen der Sprache A in drei syntaktischen Kontexten vorkommen: am Anfang, zwischen zwei „+“-Zeichen und am Ende. Um den Anfang und das Ende der Kette anzuzeigen, führen wir das Pseudo-Symbol "#" ein. Dann sind die Nachbarschaften des Symbols "a" die folgenden: #a+, +a+, +a# . Normalerweise wird dieses Symbol in der Kette unterstrichen, um das Zentrum der Nachbarschaft hervorzuheben (schließlich kann es andere solche Symbole in der Kette geben, die nicht das Zentrum sind!). Wir werden dies hier aus Mangel an einer einfachen Technik nicht tun Wahrscheinlichkeit. Das „+“-Zeichen kommt nur zwischen zwei „a“-Zeichen vor, also erhält es eine Nachbarschaft, die Zeichenkette a+a .
Betrachten Sie die Kette a+a+a und prüfen Sie, ob sie zur Sprache gehört. Das erste Zeichen "a" der Kette tritt zusammen mit der Nachbarschaft #a+ ein. Das zweite Zeichen "+" tritt zusammen mit der Nachbarschaft a+a in die Kette ein. Ein ähnliches Vorkommen kann für die restlichen Zeichen in der Zeichenfolge überprüft werden, d.h. diese Kette gehört erwartungsgemäß zur Sprache. Aber zum Beispiel die Zeichenkette a+aa gehört nicht zur Sprache A, da das letzte und vorletzte Zeichen "a" keine Nachbarschaften haben, mit denen sie in dieser Zeichenkette enthalten sind.
Nicht jede Sprache kann durch eine Nachbarschaftsgrammatik beschrieben werden. Betrachten Sie beispielsweise die Sprache B, deren Zeichenfolgen entweder mit dem Zeichen „0“ oder mit dem Zeichen „1“ beginnen. Im letzteren Fall können die Zeichen "a" und "b" weiter in der Kette gehen. Wenn die Kette bei Null beginnt, können nur die Zeichen "a" weiter gehen. Es ist nicht schwer zu beweisen, dass für diese Sprache keine Nachbarschaftsgrammatik erfunden werden kann. Die Legitimität des Auftretens des Zeichens "b" in der Kette beruht auf seinem ersten Zeichen. Für jede Nachbarschaftsgrammatik, die eine Verbindung zwischen den Zeichen "b" und "1" spezifiziert, ist es möglich, eine Kette zu wählen, die lang genug ist, so dass keine Nachbarschaft des Zeichens "b" den Anfang der Kette erreicht. Dann kann am Anfang das Symbol „0“ eingesetzt werden und die Kette gehört zur Sprache A, was nicht unseren intuitiven Vorstellungen über den syntaktischen Aufbau der Ketten dieser Sprache entspricht.
Andererseits ist es einfach, eine Zustandsmaschine zu bauen, die diese Sprache erkennt. Das bedeutet, dass die Klasse der Sprachen, die durch Nachbarschaftsgrammatiken beschrieben werden, enger ist als die Klasse der Automatensprachen. Die durch Nachbarschaftsgrammatiken definierten Sprachen werden Schraders genannt. Daher kann man in der Hierarchie der Sprachen die Klasse der Schrader-Sprachen hervorheben, die eine Unterklasse der Automatensprachen ist.
Wir können sagen, dass Schraders Sprachen eine einfache syntaktische Beziehung definieren - "in der Nähe sein" oder die Beziehung des unmittelbaren Vorrangs. Die Fernvorrangbeziehung (die offensichtlich in Sprache B existiert) kann nicht durch eine Nachbarschaftsgrammatik spezifiziert werden. Aber wenn wir uns die syntaktischen Beziehungen in den Ketten der Sprache vorstellen, dann können wir für die Beziehungsdiagramme, in die sich solche Ketten verwandeln, eine Nachbarschaftsgrammatik entwickeln.