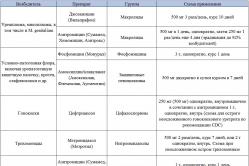
Antipyretika für Kinder werden von einem Kinderarzt verschrieben. Aber es gibt Notfallsituationen für Fieber, wenn das Kind sofort Medikamente erhalten muss. Dann übernehmen die Eltern die Verantwortung und nehmen fiebersenkende Medikamente. Was darf Säuglingen gegeben werden? Wie kann man bei älteren Kindern die Temperatur senken? Welche Medikamente sind am sichersten?
3 . Datenmodellkomponenten
Entität, Entitätsdefinition, Informationsquellen über Entitäten
Das Datenmodell – eine konzeptionelle Beschreibung des Fachgebiets – ist die abstrakteste Ebene des Datenbankdesigns. Das Datenmodell besteht aus Entitäten, Attributen, Domänen und Beziehungen. Weiter - über jedes der Elemente im Detail.
3.1 Unternehmen
Eine Entität ist etwas, worüber Informationen in einer Datenbank gespeichert werden müssen.
Beim Entwerfen von Datenbanken reicht es aus, die aktuelle Situation zu beschreiben - und die meisten Substantive und einige Verben werden Kandidaten für Entitäten sein. Zum Beispiel: "Kunden kaufen Waren. Mitarbeiter verkaufen Waren an Kunden. Lieferanten liefern Waren" - Kunden, Waren, Mitarbeiter und Lieferanten sind Einheiten. Die Verben „kaufen“ und „verkaufen“ sind ebenfalls Entitäten (obwohl sie dieselbe Entität sein können, die aus Sicht des Käufers und des Verkäufers unterschiedlich sind).
Beim Entwerfen einer Datenbank ist die Hauptinformationsquelle über Entitäten ein Gespräch mit dem Kunden, um seine Geschäftsprozesse zu verstehen. Darüber hinaus werden Standarddokumente analysiert, die in Geschäftsprozessen verwendet werden: Formulare, Berichte, Anweisungen usw. Nach Erhalt einer solchen Liste ist es notwendig, diese auf Vollständigkeit und Kohärenz zu prüfen sowie Duplikate zu identifizieren - identische Entitäten, die mit unterschiedlichen Wörtern bezeichnet werden, und Entitäten, die tatsächlich unterschiedlich sind, aber mit demselben Begriff beschrieben werden.
Entitäten können spezifische Konzepte (Kunden, Waren, Anrufe) und abstrakte Konzepte (der Agent ist für den Kunden verantwortlich, der Student ist in den Kurs eingeschrieben) modellieren.
Das Erstellen einer Datenbank beginnt mit dem Design.
Phasen des Datenbankentwurfs:
· Studium der Fachrichtung;
· Datenanalyse (Entitäten und ihre Attribute);
· Definition von Beziehungen zwischen Entitäten und Definition von primären und sekundären (Fremd-) Schlüsseln.
Während des Designprozesses wird die Struktur der relationalen Datenbank festgelegt (Zusammensetzung der Tabellen, deren Struktur und logische Verbindungen). Die Struktur einer Tabelle wird durch die Zusammensetzung der Spalten, den Datentyp und die Größe der Spalten sowie die Schlüssel der Tabelle bestimmt.
Zurück zu den Grundkonzepten Datenbankmodelle "Entity-Relationship" umfassen: Entitäten, Beziehungen zwischen ihnen und ihre Attribute (Eigenschaften).
Wesen - jedes konkrete oder abstrakte Objekt im betrachteten Fachgebiet. Entitäten sind die grundlegenden Arten von Informationen, die in der Datenbank gespeichert werden (in einer relationalen Datenbank wird jeder Entität eine Tabelle zugewiesen). Zu den Entitäten können gehören: Studenten, Kunden, Abteilungen usw. Entitätsinstanz und Entitätstyp sind unterschiedliche Konzepte. Das Konzept eines Entitätstyps bezieht sich auf eine Menge homogener Personen, Objekte oder Ereignisse, die als Ganzes agieren (z. B. ein Student, ein Kunde usw.). Eine Entitätsinstanz bezieht sich beispielsweise auf eine bestimmte Person in einer Menge. Ein Entitätstyp kann ein Student sein, und eine Instanz kann Petrov, Sidorov usw. sein.
Attribut ist eine Eigenschaft einer Entität im Fachgebiet. Sein Name muss für einen bestimmten Entitätstyp eindeutig sein. Beispielsweise können für die Entität Student folgende Attribute verwendet werden: Nachname, Vorname, Vatersname, Geburtsdatum und -ort, Passdaten usw. In einer relationalen Datenbank werden Attribute in Tabellenfeldern gespeichert.
Verbindung – die Beziehung zwischen Entitäten im Fachgebiet. Beziehungen sind Verbindungen zwischen Teilen der Datenbank (in einer relationalen Datenbank ist dies eine Verbindung zwischen Tabellendatensätzen).
Entitäten sind Daten, die nach Typ klassifiziert sind, und Beziehungen zeigen, wie diese Datentypen zueinander in Beziehung stehen. Wenn wir ein bestimmtes Fachgebiet durch eine Entität beschreiben – eine Verbindung, dann bekommen wir Modellentität - Beziehung für diese Datenbank.
Betrachten Sie das Themengebiet: Dekanat (Studentenleistung)
Die Datenbank „Dekanat“ soll Daten zu Studierenden, Studierendengruppen, Studierendennoten in verschiedenen Fachrichtungen, Lehrenden, Stipendien etc. Wir beschränken uns auf Daten zu Studierenden, Studierendengruppen und Studiennoten verschiedener Fachrichtungen. Lassen Sie uns Entitäten, Entitätsattribute und grundlegende Anforderungen für Datenbankfunktionen mit begrenzten Daten definieren.
Die wichtigsten fachbedeutsamen Einheiten der Datenbank „Dekanat“ sind: Studenten, Studentengruppen, Disziplinen, Fortschritt.
Die wichtigsten fachrelevanten Attribute von Entitäten:
-Studenten - Nachname, Vorname, Patronym, Geschlecht, Geburtsdatum und -ort, eine Gruppe von Studenten;
-Studierendengruppen - Name, Studiengang, Semester;
-Disziplinen - Name, Stundenzahl
- Fortschritt - Bewertung, Art der Kontrolle.
Grundvoraussetzungen für Datenbankfunktionen:
- Wählen Sie den Fortschritt des Schülers in den Disziplinen aus und geben Sie die Gesamtstundenzahl und die Art der Kontrolle an.
- Auswahl der Schülerleistungen nach Gruppen und Disziplinen;
- die Fächer auswählen, die von einer Gruppe von Studierenden in einem bestimmten Studiengang studiert werden, oder
bestimmten Semester.
Aus der Analyse der Sachgebietsdaten folgt, dass jeder Entität die einfachste zweidimensionale Tabelle (Beziehungen) zugeordnet werden muss. Als Nächstes müssen Sie logische Beziehungen zwischen Tabellen herstellen. Es ist notwendig, eine solche Beziehung zwischen den Tabellen „Students“ und „Fortschritt“ herzustellen, damit jeder Datensatz aus der Tabelle „Students“ mehreren Datensätzen in der Tabelle „Fortschritt“ entspricht, d. h. One-to-Many, da jeder Schüler mehrere Noten haben kann.
Die logische Beziehung zwischen Gruppenentitäten – Studenten wird als Eins-zu-Viele definiert, basierend auf der Tatsache, dass es viele Studenten in der Gruppe gibt und jeder Student Teil einer Gruppe ist. Die logische Beziehung zwischen den Entitäten Disziplinen - Fortschritt ist als Eins-zu-Viele definiert, da für jede Disziplin mehrere Noten an verschiedene Schüler vergeben werden können.
Darauf aufbauend erstellen wir ein Entity-Relationship-Modell für die Datenbank des Dekanats
Pfeil ist Symbol Beziehungen: Eins-zu-viele.
Um eine Datenbank zu erstellen, müssen Sie eines der bekannten DBMS verwenden, zum Beispiel das Access-DBMS.
Der Begriff „relational“ bedeutet „beziehungsbasiert“. Eine relationale Datenbank besteht aus Entitäten (Tabellen), die in irgendeiner Beziehung zueinander stehen. Der Name kam von englisches Wort Beziehung.
Das Datenbankdesign besteht aus zwei Hauptphasen: der logischen und der physischen Modellierung.
Bei der logischen Modellierung sammeln Sie Anforderungen und entwickeln ein Datenbankmodell, das unabhängig von einem bestimmten DBMS (Relational Database Management System) ist. Es ist wie das Erstellen von Blaupausen für Ihr Haus. Sie könnten alles überdenken und zeichnen: wo die Küche, die Schlafzimmer, das Wohnzimmer sein werden. Aber das ist alles auf Papier und in Layouts.
Während der physischen Modellierung erstellen Sie ein Modell, das für eine bestimmte Anwendung und ein DBMS optimiert ist. Dieses Modell wird in der Praxis umgesetzt. Wenn wir aus dem vorherigen Absatz zum Haus zurückkehren, müssen Sie zu diesem Zeitpunkt irgendwo ein Haus bauen - Baumstämme, Ziegel tragen ...
Der Datenbankentwurfsprozess besteht aus den folgenden Schritten:
- Sammlung von Informationen;
- Definition von Entitäten;
- Definieren von Attributen für jede Entität;
- Definieren von Beziehungen zwischen Entitäten;
- Normalisierung;
- Transformation in ein physikalisches Modell;
- Datenbankerstellung.
Die ersten 5 Phasen bilden die Phase des logischen Entwurfs und die verbleibenden zwei die Phase der physischen Modellierung.
Logikphase
Die logische Phase besteht aus mehreren Phasen. Sie werden alle unten besprochen.
Anforderungen sammeln
In diesem Stadium müssen Sie genau festlegen, wie die Datenbank verwendet und welche Informationen darin gespeichert werden. Sammeln Sie so viele Informationen wie möglich darüber, was das System tun sollte und was nicht.
Entitätsdefinition
In diesem Stadium müssen Sie die Entitäten definieren, aus denen die Datenbank bestehen soll.
Eine Entität ist ein Objekt in einer Datenbank, das Daten speichert. Eine Entität kann etwas Reales (ein Haus, eine Person, ein Objekt, ein Ort) oder eine abstrakte Sache (eine Banktransaktion, eine Abteilung eines Unternehmens, eine Buslinie) sein. Im physikalischen Modell wird eine Entität als Tabelle bezeichnet.
Entitäten bestehen aus Attributen (Spalten in einer Tabelle) und Datensätzen (Zeilen in einer Tabelle).
Typischerweise bestehen Datenbanken aus mehreren primären Entitäten, die einer großen Anzahl untergeordneter Entitäten zugeordnet sind. Kerneinheiten werden als unabhängig bezeichnet: Sie sind von keiner anderen Einheit abhängig. Untergeordnete Entitäten werden als abhängig bezeichnet: Damit eine von ihnen existiert, muss die damit verbundene Haupttabelle existieren.
In Diagrammen werden Entitäten normalerweise als Rechtecke dargestellt. Der Name der Entität wird innerhalb des Rechtecks angezeigt:
Jede Tabelle hat die folgenden Eigenschaften:
- es gibt keine identischen Zeilen darin;
- alle Spalten (Attribute) in der Tabelle müssen unterschiedliche Namen haben;
- Elemente innerhalb derselben Spalte haben denselben Typ (Zeichenfolge, Zahl, Datum);
- Die Reihenfolge der Zeilen in der Tabelle kann beliebig sein.
In diesem Stadium müssen Sie alle Kategorien von Informationen (Entitäten) identifizieren, die in der Datenbank gespeichert werden.
Attributdefinition
Ein Attribut stellt eine Eigenschaft dar, die eine Entität beschreibt. Attribute sind oft eine Zahl, ein Datum oder Text. Alle in einem Attribut gespeicherten Daten müssen vom gleichen Typ sein und die gleichen Eigenschaften haben.
Im physikalischen Modell werden Attribute Spalten genannt.
Nach der Definition der Entitäten ist es notwendig, alle Attribute dieser Entitäten zu definieren.
In Diagrammen werden Attribute normalerweise innerhalb des Entitätsrechtecks aufgelistet. In der Abbildung finden Sie ein Beispiel der Datenbank „Häuser“, nur dass jetzt einige Attribute für die Entitäten aus dieser Datenbank definiert sind. 
Jedes Attribut definiert den Datentyp, die Größe, zulässige Werte und andere Regeln. Dazu gehören obligatorische, veränderliche und Eindeutigkeitsregeln.
Die obligatorische Regel bestimmt, ob ein Attribut ein erforderlicher Teil einer Entität ist. Wenn das Attribut ein optionaler Teil der Entität ist, kann es NULL sein, andernfalls nicht.
Sie müssen auch feststellen, ob das Attribut änderbar ist. Einige Attributwerte können sich nicht ändern, nachdem der Eintrag erstellt wurde.
Und schließlich müssen Sie bestimmen, ob das Attribut eindeutig ist. Wenn dies der Fall ist, können die Attributwerte nicht wiederholt werden.
Schlüssel
Ein Schlüssel ist ein Satz von Attributen, die einen Eintrag eindeutig identifizieren. Schlüssel werden in zwei Klassen eingeteilt: einfach und zusammengesetzt.
Ein einfacher Schlüssel besteht nur aus einem Attribut. In der Datenbank „Pässe der Bürger des Landes“ ist die Passnummer beispielsweise ein einfacher Schlüssel: Schließlich gibt es keine zwei Pässe mit derselben Nummer.
Ein zusammengesetzter Schlüssel besteht aus mehreren Attributen. In derselben Datenbank "Pässe der Bürger des Landes" kann ein zusammengesetzter Schlüssel mit folgenden Attributen vorhanden sein:
Nachname, Vorname, Vatersname, Geburtsdatum. Dies ist nur ein Beispiel, da dieser zusammengesetzte Schlüssel theoretisch keine garantierte Eindeutigkeit des Datensatzes bietet.
Es gibt auch mehrere Arten von Schlüsseln, die im Folgenden beschrieben werden.
Möglicher Schlüssel
Ein Kandidatenschlüssel ist ein beliebiger Satz von Attributen, der einen Eintrag in einer Tabelle eindeutig identifiziert. Der Kandidatenschlüssel kann einfach oder zusammengesetzt sein.
Jede Entität muss mindestens einen möglichen Schlüssel haben, obwohl es mehr als einen möglichen Schlüssel geben kann. Keines der Primärschlüsselattribute darf einen NULL-Wert haben.
Ein Kandidatenschlüssel wird auch als Ersatzschlüssel bezeichnet.
Primärschlüssel
Ein Primärschlüssel ist ein Satz von Attributen, die einen Datensatz in einer Tabelle (Entität) eindeutig identifizieren. Einer der möglichen Schlüssel wird zum Primärschlüssel. In Diagrammen werden Primärschlüssel oft über der Hauptliste von Attributen angezeigt oder mit speziellen Symbolen hervorgehoben. Die Entität in der Abbildung hat sowohl Schlüssel- als auch reguläre Attribute. 
Alternative Schlüssel
Jeder mögliche Schlüssel, der nicht der Primärschlüssel ist, wird als alternativer Schlüssel bezeichnet. Eine Entität kann mehrere alternative Schlüssel haben.
Fremde Schlüssel
Ein Fremdschlüssel ist eine Sammlung von Attributen, die auf den Primär- oder Alternativschlüssel einer anderen Entität verweisen. Wenn ein Fremdschlüssel keiner primären Entität zugeordnet ist, kann er nur Nullwerte enthalten. Wenn der Schlüssel auch zusammengesetzt ist, müssen alle Attribute des Fremdschlüssels undefiniert sein.
In Diagrammen werden Attribute, die zu Fremdschlüsseln zusammengefasst sind, durch Sonderzeichen gekennzeichnet. Die Abbildung zeigt zwei verwandte Entitäten (Häuser und ihre Eigentümer) und die von ihnen gebildeten Fremdschlüssel (schließlich kann eine Person mehr als ein Haus besitzen). 
Schlüssel sind logische Konstrukte, keine physischen Objekte. Relationale Datenbanken verfügen über Mechanismen zum Speichern von Schlüsseln.
Definieren von Beziehungen zwischen Entitäten
Relationale Datenbanken ermöglichen es Ihnen, Informationen zu kombinieren, die zu verschiedenen Entitäten gehören.
Eine Beziehung ist eine Situation, in der eine Entität auf den Primärschlüssel einer zweiten Entität verweist. Wie zum Beispiel die Entitäten House und Master in der vorherigen Abbildung.
Beziehungen werden während des Basisdesignprozesses definiert. Dazu sollten Sie die Entitäten analysieren und die logischen Beziehungen identifizieren, die zwischen ihnen bestehen.
Der Beziehungstyp bestimmt die Anzahl der Entitätsdatensätze, die einem anderen Entitätsdatensatz zugeordnet sind. Beziehungen werden in drei Haupttypen unterteilt, die im Folgenden beschrieben werden.
Eins zu eins
Jeder Eintrag der ersten Entität entspricht nur einem Eintrag der zweiten Entität. Und jeder Datensatz der zweiten Entität entspricht nur einem Datensatz der ersten Entität. Beispielsweise gibt es zwei Entitäten: Personen und Geburtsurkunden. Und eine Person kann nur eine Geburtsurkunde haben.
Einer zu vielen
Jeder Datensatz der ersten Entität kann mehreren Datensätzen der zweiten Entität entsprechen. Jeder Eintrag der zweiten Entität entspricht jedoch nur einem Eintrag der ersten Entität. Beispielsweise gibt es zwei Entitäten: Bestellung und Bestellartikel. Und es kann viele Artikel in einer Bestellung geben.
viel zu viel
Jeder Datensatz der ersten Entität kann mehreren Datensätzen der zweiten Entität entsprechen. Jedoch kann jeder Datensatz der zweiten Entität mehreren Datensätzen der ersten Entität entsprechen. Beispielsweise gibt es zwei Entitäten: Autor und Buch. Ein Autor kann viele Bücher schreiben. Aber ein Buch kann mehrere Autoren haben.
Nach dem Kriterium der obligatorischen Beziehungen werden in obligatorische und optionale Beziehungen unterteilt.
- Eine obligatorische Beziehung bedeutet, dass es für jeden Eintrag der ersten Entität verwandte Einträge in der zweiten Entität geben muss.
- Eine optionale Beziehung bedeutet, dass ein Datensatz aus der ersten Entität möglicherweise keinen Datensatz in der zweiten Entität hat.
Normalisierung
Normalisierung ist der Vorgang des Entfernens redundanter Daten aus einer Datenbank. Jedes Datenelement muss in einer einzigen Instanz in der Datenbank gespeichert werden. Es gibt fünf gängige Formen der Normalisierung. In der Regel wird die Datenbasis auf die dritte Normalform reduziert.
Während des Normalisierungsprozesses werden bestimmte Aktionen durchgeführt, um redundante Daten zu entfernen. Die Normalisierung verbessert die Leistung, beschleunigt das Sortieren und Erstellen von Indizes, reduziert die Anzahl der Indizes pro Entität und beschleunigt Einfüge- und Aktualisierungsvorgänge.
Eine normalisierte Datenbank ist normalerweise flexibler. Beim Ändern von Abfragen oder persistenten Daten erfordert eine normalisierte Datenbank in der Regel weniger Änderungen, und Änderungen haben weniger Konsequenzen.
Erste Normalform
Um eine Entität in die erste Normalform umzuwandeln, müssen Sie doppelte Wertegruppen eliminieren und sicherstellen, dass jedes Attribut nur einen Wert enthält, Wertelisten sind nicht zulässig.
Mit anderen Worten, jedes Attribut in einer Entität sollte nur in einer Instanz gespeichert werden.
In der Abbildung ist beispielsweise die Hausentität nicht normalisiert. Es enthält mehrere Attribute zum Speichern von Daten über die Eigentümer des Hauses (die Entität Haus entspricht nicht der ersten Normalform). 
Um die Hausentität in die erste normale Form zu bringen, ist es notwendig, die wiederholten Wertegruppen zu entfernen, d. h. die Attribute Besitzer 1-3 zu entfernen und sie in einer separaten Entität zu platzieren. Ergebnis (Entity House auf erste Normalform reduziert): 
Zweite Normalform
Eine Tabelle in zweiter Normalform enthält nur die Daten, die auf sie zutreffen. Werte von Nicht-Schlüssel-Entitätsattributen hängen vom Primärschlüssel ab. Genauer gesagt hängen Attribute vom Primärschlüssel, vom gesamten Primärschlüssel und nur vom Primärschlüssel ab.
Entitäten müssen sich in der ersten Normalform befinden, um der zweiten Normalform zu entsprechen.
Beispielsweise hat die Entität Haus in der Abbildung ein Attribut Preis pro Liter Benzin, das nichts mit Häusern zu tun hat. Dieses Attribut wird entfernt (oder Sie können es in eine andere Entität verschieben). Außerdem verschieben wir das Bürgermeisterattribut in eine separate Entität - dieses Attribut hängt von der Stadt ab, in der sich das Haus befindet, und nicht vom Haus.
Die Abbildung zeigt das Essenzhaus in der zweiten Normalform (das Essenzhaus reduziert auf die zweite Normalform). 
dritte Normalform
Die dritte Normalform schließt Attribute aus, die nicht vom gesamten Schlüssel abhängen. Jedes Wesen, das sich in der dritten Normalform befindet, befindet sich auch in der zweiten Normalform. Dies ist die häufigste Form einer Datenbank.
In der dritten Normalform hängt jedes Attribut vom Schlüssel ab, vom ganzen Schlüssel und von nichts als dem Schlüssel.
Beispielsweise hat die Entität „Hausbesitzer“ in der Abbildung ein Sternzeichenattribut, das vom Geburtsdatum des Eigentümers des Hauses abhängt und nicht von seinem Namen (der der Schlüssel ist).
Um die Entität Hausbesitzer zu casten, müssen Sie die Entität Sternzeichen anlegen und dort das Attribut Sternzeichen (Entität Hausbesitzer, reduziert auf die dritte Normalform) übertragen: 
Beschränkungen
Einschränkungen sind die vom Datenbankverwaltungssystem erzwungenen Regeln. Einschränkungen definieren den Satz von Werten, die in eine Spalte oder Spalten eingegeben werden können.
Sie möchten beispielsweise nicht, dass die Bestellmenge in Ihrem sehr coolen Geschäft weniger als 500 Rubel beträgt. Sie legen einfach ein Limit in der Spalte Bestellbetrag fest.
Gespeicherte Prozeduren
Gespeicherte Prozeduren sind vorkompilierte Prozeduren, die in einer Datenbank gespeichert sind. Gespeicherte Prozeduren können zum Definieren verwendet werden Geschäftsregeln, mit deren Hilfe komplexere Berechnungen möglich sind als nur mit Hilfe von Constraints.
Gespeicherte Prozeduren können sowohl Programmablauflogik als auch Datenbankabfragen enthalten. Sie können Parameter übernehmen und Ergebnisse als Tabellen oder einzelne Werte zurückgeben.
Gespeicherte Prozeduren sind genau wie normale Prozeduren oder Funktionen in jedem Programm.
HINWEIS
Gespeicherte Prozeduren befinden sich in der Datenbank und werden auf dem Datenbankserver ausgeführt. Sie sind im Allgemeinen schneller als SQL-Anweisungen, da sie in kompilierter Form gespeichert werden.
Datenintegrität
Indem wir die Daten in Tabellen organisieren und die Beziehungen zwischen ihnen definieren, können wir davon ausgehen, dass ein Modell erstellt wurde, das das Geschäftsumfeld korrekt widerspiegelt. Jetzt müssen wir sicherstellen, dass die in die Datenbank eingegebenen Daten ein korrektes Bild des Sachverhalts vermitteln. Mit anderen Worten, Sie müssen Geschäftsregeln durchsetzen und die Integrität der Datenbank aufrechterhalten.
Ihr Unternehmen beschäftigt sich beispielsweise mit der Lieferung von Büchern. Es ist unwahrscheinlich, dass Sie eine Bestellung eines unbekannten Kunden annehmen, da Sie die Bestellung dann nicht einmal ausliefern können. Daher die Geschäftsregel: Bestellungen werden nur von Kunden angenommen, deren Informationen in der Datenbank vorhanden sind.
Die Korrektheit der Daten in relationalen Datenbanken wird durch ein Regelwerk sichergestellt. Datenintegritätsregeln fallen in vier Kategorien.
- Entitätsintegrität- Jeder Entitätsdatensatz muss eine eindeutige Kennung haben und Daten enthalten. Schließlich müssen Sie irgendwie zwischen all diesen Datensätzen in der Datenbank unterscheiden.
- Attributintegrität- Jedes Attribut akzeptiert nur gültige Werte. Beispielsweise darf der Kaufbetrag auf keinen Fall kleiner als null sein.
- Referentielle Integrität- eine Reihe von Regeln, die die logische Konsistenz von Primär- und Fremdschlüsseln beim Einfügen, Aktualisieren und Löschen von Datensätzen sicherstellen. Die referentielle Integrität stellt sicher, dass es für jeden Fremdschlüssel einen entsprechenden Primärschlüssel gibt. Nehmen wir das vorherige Beispiel mit den Entitäten Eigenheimbesitzer und Haus. Nehmen wir an, Sie sind Vasya Ivanov und besitzen ein Haus. Sie haben Ihren Nachnamen in Sidorov geändert und die entsprechenden Änderungen an der Entität Hausbesitzer vorgenommen. Auf jeden Fall möchten Sie, dass Ihr Haus unter Ihrem neuen Namen weiterhin Ihnen gehört und nicht einem gewissen Vasya Ivanov gehört, den es nicht mehr gibt.
- Benutzerdefinierte Integritätsregeln- alle Integritätsregeln, die keiner der aufgeführten Kategorien angehören.
löst aus
Abzug ist ein Analogon einer gespeicherten Prozedur, die automatisch aufgerufen wird, wenn sich die Daten in der Tabelle ändern.
Trigger sind ein leistungsfähiger Mechanismus zum Aufrechterhalten der Datenbankintegrität. Trigger werden vor oder nach Datenänderungen in der Tabelle aufgerufen.
Mit Hilfe von Triggern können Sie diese Änderungen nicht nur rückgängig machen, sondern auch die Daten in jeder anderen Tabelle ändern.
Sie erstellen beispielsweise ein Internetforum und möchten sicherstellen, dass die Forenliste den neuesten Forumsbeitrag anzeigt. Natürlich können Sie eine Nachricht von der Entität „Forenbeiträge“ entgegennehmen, aber dies erhöht die Komplexität Ihrer Anfrage und ihre Ausführungszeit. Es ist einfacher, der Entität „Forenbeiträge“ einen Auslöser hinzuzufügen, der den letzten zur Entität „Foren“ hinzugefügten Beitrag im Attribut „Letzter Beitrag“ aufzeichnet. Dies vereinfacht die Abfrage erheblich.
Geschäftsregeln
Geschäftsregeln definieren die Beschränkungen, die den Daten gemäß den Anforderungen des Unternehmens auferlegt werden (jene, für die Sie die Basis erstellen). Geschäftsregeln können aus einer Reihe von Schritten bestehen, die zum Ausführen einer bestimmten Aufgabe erforderlich sind, oder sie können einfach Überprüfungen sein, die überprüfen, ob die eingegebenen Daten korrekt sind. Geschäftsregeln können Datenintegritätsregeln umfassen. Im Gegensatz zu anderen Regeln sollen sie in erster Linie sicherstellen, dass Geschäftstransaktionen korrekt durchgeführt werden.
Beispielsweise kann es im Unternehmen Very Tough Guys üblich sein, dass nur weiße, blaue und schwarze Autos für den offiziellen Gebrauch gekauft werden.
Die Geschäftsregel für das Attribut „Fahrzeugfarbe“ der Entität „Firmenfahrzeuge“ wäre dann, dass das Fahrzeug nur weiß, blau oder schwarz sein kann.
Die meisten DBMSs bieten folgende Möglichkeiten:
- um Standardwerte anzugeben;
- die Daten vor der Eingabe in die Datenbank zu prüfen;
- um Beziehungen zwischen Tabellen aufrechtzuerhalten;
- die Einzigartigkeit von Werten sicherzustellen;
- zum Speichern gespeicherter Prozeduren direkt in der Datenbank.
Alle diese Funktionen können verwendet werden, um Geschäftsregeln in einer Datenbank zu implementieren.
Physikalisches Modell
Der nächste Schritt nach dem Erstellen des logischen Modells besteht darin, das physische Modell zu erstellen. Das physikalische Modell ist praktische Anwendung Datenbank. Das physische Modell definiert alle Objekte, die Sie implementieren müssen.
Beim Übergang von einem logischen Modell zu einer physischen Entität werden sie in Tabellen und Attribute in Spalten umgewandelt.
Beziehungen zwischen Entitäten können in Tabellen konvertiert oder als Fremdschlüssel belassen werden.
Primärschlüssel werden in Primärschlüsseleinschränkungen konvertiert. Mögliche Schlüssel befinden sich in Eindeutigkeitsbeschränkungen.
Denormalisierung
Denormalisierung- Dies ist eine absichtliche Änderung der Struktur der Basis, die gegen die Regeln der Normalformen verstößt. Dies geschieht normalerweise, um die Datenbankleistung zu verbessern.
Theoretisch sollte man immer eine voll normalisierte Basis anstreben, aber in der Praxis bedeutet eine voll normalisierte Basis fast immer einen Leistungsabfall. Eine übermäßige Normalisierung einer Datenbank kann dazu führen, dass bei jedem Datenabruf auf mehrere Tabellen zugegriffen wird. Typischerweise müssen vier Tabellen oder weniger an einer Abfrage teilnehmen.
Standard-Denormalisierungstechniken sind: Kombinieren mehrerer Tabellen zu einer, Speichern derselben Attribute in mehreren Tabellen und Speichern von zusammengefassten oder berechneten Daten in einer Tabelle.
Der dokumentarische Ansatz, der auf der klassischen Betrachtung des Fachgebiets basiert, beinhaltet die Erstellung von Entitätstypen, die auf den Attributen jedes Dokuments basieren und eine allgemeine Menge solcher Entitätstypen (Attributentitäten) bilden, deren Vereinigung eine Beziehung in der ersten Normalen darstellt Form (Abb. 4.2).
In diesem Beispiel ergab eine vorläufige Analyse von Dokumenten eine Reihe von Attributen, die beim Erstellen eines Datenbankmodells präsentiert werden müssen. Lassen Sie uns ein Datenbankmodell für die Bildung des Dokuments D1 "Bestellung" erstellen. Das Dokument enthält 10 Attribute, von denen jedes durch einen separaten Entitätstyp dargestellt wird, der das entsprechende einfache Typattribut enthält. Diese Darstellung kann jedoch nicht als absolut korrekt angesehen werden, da es ein Attribut im Dokument gibt, das nicht berücksichtigt werden sollte, da es nur innerhalb des Dokuments sinnvoll ist und einen bestimmten Fall der Beziehung in seiner Darstellung im Dokument charakterisiert. Dieses Attribut ist "Artikelnummer". Tatsächlich wird seine Darstellung im Dokument, dies zeigt die Analyse des Dokuments, im Prozess der Widerspiegelung der bestellten Waren implementiert, und die Nummerierung wird in Bezug auf das Dokument als Objekt des Themenbereichs und nicht der Lagerung gebildet Bereich für Informationen zur bestellten Ware. Da das Beispiel also nicht die Aufgabe hat, Informationen über das Objekt „Dokument“ und dessen Präsentation für den Benutzer zu speichern, ist das Attribut „Artikelnummer“ aus Sicht des Auftrags- und Produktbezugs bedeutungslos. Wir werden es jetzt jedoch nicht aus der Liste der berücksichtigten Attribute und Entitätstypen entfernen, da wir es als ein Attribut betrachten, das die Reihenfolge der Waren in einer Bestellung charakterisiert.
Beim Extrahieren von Entitätstypen aus Dokumentattributen fügt der Entwickler den bereits im Dokument vorhandenen Merkmalen ein weiteres Merkmal hinzu, und die Beschreibung von Entitätstypen wird etwas vollständiger (Tabelle 4.5), wobei ihre spätere Repräsentation im Modell berücksichtigt wird.
Tabelle 4.5
|
Beschreibung der Entitätstypen
|
Diese Beschreibung stellt die Eigenschaften dar, die für das Datenbankmodell wichtig sind:
- Datentyp – eine Beschreibung in Form des Datenbankmodells der Arten gespeicherter Informationen, die auf der Ebene der physischen Implementierung die Prinzipien der Darstellung und Verarbeitung in der Datenbank definieren;
- Dimension - ein Merkmal, das für einige Datentypen verwendet wird, um die Anzahl der Zeichen (Bytes) anzugeben, die beim Speichern des entsprechenden Werts verwendet werden sollen.
In der dargestellten Entitätstyp-Beschreibungstabelle enthält die Spalte „Dimension“ für einige Datentypen einen numerischen Wert, der in geschweiften Klammern eingeschlossen ist. Dies geschieht aus dem Grund, dass ganzzahlige, logische Daten sowie Datum und Uhrzeit in Datenbanken durch Standarddarstellungsmechanismen dargestellt werden und die Größe in Bytes zum Speichern von Daten dieser Art immer bekannt ist.
Numerische Datentypen und der ihnen gleichgestellte logische Datentyp haben immer eine feste Dimension:
- Boolean, Logical, Tinylnt, Bit – logische (Boolean, Logical) Daten können die Werte „True“ (true) und „False“ (false) enthalten, die mit einer kleinen Ganzzahl (Tinylnt) oder Bit (Bit) identisch sind eine Mindestgröße von 1 Byte (1 Bit, wenn identisch mit dem Bit-Typ) und die Werte „0“ oder „1“;
- Bit ist ein ganzzahliger Datentyp, der die Werte "0" oder "1" mit einer Dimension von 1 Bit darstellt;
- Tinylnt ist ein ganzzahliger Datentyp mit einer Dimension von 1 Byte;
- SmallInt ist ein ganzzahliger Datentyp mit einer Dimension von 2 Bytes;
- Integer – ein Integer-Datentyp mit einer Dimension von 4 Bytes;
- BigInt, Long - ganzzahliger Typ mit großer Dimension (8 Bytes);
- Datum - Datumsdatentyp, dargestellt in einer Zeichenversion, mit einer Dimension von 8 Zeichen (Bytes);
- Zeit - Zeitdatentyp, dargestellt in Zeichenform, mit einer Dimension von 8 Zeichen (Bytes).
Bei Datentypen mit fester Dimension wird die Spalte "Dimension" normalerweise nicht ausgefüllt, was bedeutet, dass die Angabe des Datentyps selbst diesen bereits definiert und keine zusätzliche Angabe erforderlich ist. Bei allen anderen Datentypen ist es wichtig, die maximale Dimension unter Berücksichtigung der Besonderheiten der Werte anzugeben, die möglicherweise im Dokument vorhanden sind. Bei numerischen Datentypen geben Sie die Anzahl der Bytes an, die die Zahl belegen soll, sowie die Anzahl der Nachkommastellen, wodurch die Genauigkeit der reellen Zahl festgelegt wird. Zeichendatentypen geben die Anzahl der Zeichen an, die für das entsprechende Attribut gespeichert werden sollen. Ein Zeichentyp kann auf drei verschiedene Arten dargestellt werden:
Text, CLOB - ein Textdatentyp, der große Textinformationen darstellt, die auf besondere Weise gespeichert sind, und in der Datenbanktabelle als Satz von Anfangsbuchstaben angezeigt wird, deren Anzahl die Dimension des Attributs dieses Typs ist;
- - Zeichen – ein String-Datentyp, der genau die Anzahl von Zeichen speichert, die als Dimension angegeben ist, wobei die fehlenden Zeichen am Ende des Strings mit Leerzeichen aufgefüllt werden;
- - Varchar - String-Datentyp variabler Länge, bei dem die Dimension die maximale Anzahl von Zeichen bestimmt, die ein gespeicherter String haben kann.
Die Typen Character und Varchar sind sich im Wesentlichen sehr ähnlich, da sie den Typ von String-Daten definieren, aber die Einzelheiten der Datendarstellung bestimmen die Bedingungen, unter denen der eine oder andere Typ verwendet wird. Um also Daten fester Größe zu speichern (z. B. TIN (Steueridentifikationsnummer), BNK (Bankleitzahl) einer Bank, Bestellnummer, Produktartikel usw.), wird üblicherweise der Typ Character verwendet, da z Daten können nicht angegeben werden. Möglicherweise gibt es Optionen, wenn die Anzahl der Zeichen von der in der Dimension des Attributs angegebenen abweichen kann. Der Varchar-Typ wird in allen anderen Fällen verwendet, in denen es nicht erforderlich ist, die genaue Anzahl von Zeichen zu speichern.
Bezeichnungen.Kerneinheit (Kernel) ist eine unabhängige Einheit (sie wird weiter unten ausführlicher definiert).
In den zuvor betrachteten Beispielen sind die Stäbe „Student“, „Wohnung“, „Männer“, „Arzt“, „Ehe“ (aus Beispiel 2.2) und andere, deren Namen in Rechtecken platziert sind.
Assoziative Einheit (Verband) ist eine Viele-zu-Viele-Beziehung ("-to-many" usw.) zwischen zwei oder mehr Entitäten oder Entitätsinstanzen (wie in Beispiel 2.4). Verbände werden als vollständige Einheiten behandelt:
sie können an anderen Vereinigungen und Benennungen in gleicher Weise wie Kerneinheiten teilnehmen;
kann Eigenschaften haben, d.h. haben nicht nur eine Reihe von Schlüsselattributen, die benötigt werden, um Beziehungen anzuzeigen, sondern auch eine beliebige Anzahl anderer Attribute, die die Beziehung charakterisieren. Beispielsweise enthalten die Assoziationen „Heirat“ aus den Beispielen 2.1 und 2.4 die Schlüsselattribute „Code_M“, „Code_F“ und „Personalnummer des Ehemanns“, „Personalnummer der Ehefrau“, sowie qualifizierende Attribute „Bescheinigungsnummer“, „Meldedatum“. “, „Meldeort“, „Nummer der Eintragung im Standesamtsbuch“, usw.
Charakteristische Entität (charakteristisch) ist eine Viele-zu-Eins- oder Eins-zu-Eins-Beziehung zwischen zwei Entitäten (ein Sonderfall einer Zuordnung). Der einzige Zweck eines Merkmals innerhalb des betrachteten Sachgebietes ist es, eine andere Entität zu beschreiben oder zu verdeutlichen. Die Notwendigkeit für sie ergibt sich aus der Tatsache, dass die Entitäten der realen Welt manchmal mehrwertige Eigenschaften haben. Ein Ehemann kann mehrere Ehefrauen haben (Beispiel 2.3), ein Buch kann mehrere Nachdruckmerkmale haben (korrigiert, ergänzt, überarbeitet, ...) usw.
Die Existenz eines Merkmals hängt ausschließlich von der zu charakterisierenden Entität ab: Frauen verlieren den Status von Ehefrauen, wenn ihr Ehemann stirbt.
Zur Beschreibung des Merkmals wird ein neuer JIM-Vorschlag verwendet, der in Allgemeiner Fall Ansicht:
CHARAKTERISTIK (Attribut 1, Attribut 2, ...) (LISTE VON CHARAKTERISIERTEN ENTITÄTEN).
Wir werden auch die Sprache der ER-Diagramme erweitern, indem wir ein Trapez für das Bild des Merkmals einführen (Abb. 2.2).
Reis. 2.2. Elemente der Extended ER Diagram Language
Wesen bezeichnen oder Bezeichnung ist eine Viele-zu-Eins- oder Eins-zu-Eins-Beziehung zwischen zwei Entitäten und unterscheidet sich von einem Merkmal dadurch, dass es nicht von der bezeichneten Entität abhängt.
Betrachten Sie ein Beispiel im Zusammenhang mit der Registrierung von Mitarbeitern in verschiedenen Abteilungen einer Organisation.
In Ermangelung strenger Regeln (ein Mitarbeiter kann gleichzeitig in mehreren Abteilungen oder in keiner Abteilung eingeschrieben sein) müssen Sie eine Beschreibung mit dem Verein Einschreibung erstellen:
Abteilungen (Abteilungsnummer, Abteilungsname, ...) Mitarbeiter (Personalnummer, Nachname, ...) Einschreibung [Abteilung M, Mitarbeiter N] (Abteilungsnummer, Personalnummer, Einschreibungsdatum).
Sofern jedoch jeder der Mitarbeiter in einer der Abteilungen eingeschrieben sein muss, können Sie eine Beschreibung mit der Bezeichnung Mitarbeiter erstellen:
Abteilungen (Abteilungsnummer, Abteilungsname, ...) Mitarbeiter (Personalnummer, Nachname, ... , Abteilungsnummer, Immatrikulationsdatum) [Abteilungen]
In diesem Beispiel haben die Mitarbeiter eine eigenständige Existenz (wird eine Abteilung gelöscht, müssen nicht zwangsläufig auch die Mitarbeiter dieser Abteilung gelöscht werden). Sie können daher keine Merkmale von Abteilungen sein und werden als Bezeichnungen bezeichnet.
Bezeichnungen werden verwendet, um wiederholte Werte großer Textattribute zu speichern: "Kodifikatoren" von Disziplinen, die von Studenten studiert werden, Namen von Organisationen und ihren Abteilungen, Warenlisten usw.
Die Beschreibung der Bezeichnung unterscheidet sich äußerlich von der Beschreibung des Merkmals nur dadurch, dass die bezeichneten Stellen nicht in geschweifte Klammern, sondern in eckige Klammern gesetzt werden:
BEZEICHNUNG (Attribut 1, Attribut 2, ...)[LISTE DER BESTIMMTEN EINHEITEN].
Notationen werden in der Regel nicht als vollwertige Entitäten behandelt, obwohl dies zu keinem Fehler führen würde.
Bezeichnungen und Merkmale sind keine völlig unabhängigen Entitäten, da sie das Vorhandensein einer anderen Entität voraussetzen, die „benannt“ oder „charakterisiert“ wird. Sie sind aber immer noch Sonderfälle einer Entität und können natürlich Eigenschaften haben, an Assoziationen teilnehmen, Bezeichnungen haben und eigene (untergeordnete) Eigenschaften haben. Wir betonen auch, dass alle Instanzen eines Merkmals zwangsläufig mit irgendeiner Instanz der zu charakterisierenden Entität assoziiert sein müssen. Es ist jedoch zulässig, dass einige Instanzen der gekennzeichneten Entität keine Verknüpfungen aufweisen. Es stimmt, wenn es um Ehen geht, sollte die Essenz von "Ehemännern" durch die Essenz von "Männern" ersetzt werden (es gibt keinen Ehemann ohne Ehefrau).
Lassen Sie uns nun eine Kernentität neu definieren als eine Entität, die weder eine Assoziation noch eine Bezeichnung noch ein Merkmal ist. Solche Entitäten haben eine unabhängige Existenz, obwohl sie sich auf andere Entitäten beziehen können, wie beispielsweise Mitarbeiter auf Abteilungen verweisen.
Betrachten wir abschließend ein Beispiel für den Aufbau eines infologischen Modells der Datenbank „Lebensmittel“, in der Informationen über Gerichte (Abb. 2.3), deren täglichen Verzehr, die Produkte, aus denen diese Gerichte zubereitet werden, und die Lieferanten dieser Produkte enthalten sein sollten gelagert. Die Informationen werden vom Küchenchef und dem Manager des kleinen Catering-Betriebs sowie von seinen Besuchern verwendet.
Reis. 2.3. Rezeptbeispiel
Mit Hilfe dieser Benutzer wurden die folgenden Objekte und Merkmale der entworfenen Basis identifiziert:
- Gerichte, zu deren Beschreibung Daten in ihren Rezepten erforderlich sind: Nummer des Gerichts (z. B. aus einem Rezeptbuch), Name des Gerichts, Art des Gerichts (Vorspeise, Suppe, Hauptgericht usw.), Portionsgewicht), Name, Kaloriengehalt und Gewicht jedes Produkts, das in dem Gericht enthalten ist.
- Für jeden Produktlieferanten: Name, Adresse, Name des gelieferten Produkts, Lieferdatum und Preis zum Zeitpunkt der Lieferung.
- Tägliche Nahrungsaufnahme (Verzehr): Gericht, Anzahl der Portionen, Datum.
Durch die Analyse von Objekten können Sie Folgendes hervorheben:
- Bars von Gerichten, Produkten und Städten;
- Assoziationszusammensetzung (verbindet Gerichte mit Produkten) und
Lieferungen (verbindet Lieferanten mit Produkten);
- Bezeichnung Lieferanten;
- Eigenschaften Rezepte und Verbrauch.
Das ER-Diagramm des Modells ist in Abb. 1 dargestellt. 2.4. und das Modell in der JIM-Sprache hat die folgende Form:
Gerichte (BL, Gericht, Art) Produkte (PR, Produkt, Kalorien) Lieferanten (PIC, Stadt, Lieferant) [Stadt] Zusammensetzung [Gerichte M, Produkte N] (BL, PR, Gewicht (g)) Lieferungen [Lieferanten M, Produkte N] (POS, PR, Datum_P, Preis, Gewicht (kg)) Städte (Stadt, Land) Rezepte (BL, Rezept) (Gerichte) Verbrauch (BL, Datum_R, Portionen) (Gerichte)
In diesen Modellen sind Gericht, Produkt und Lieferant Namen, und BL, PR und POS sind digitale Codes von Gerichten, Produkten und Organisationen, die diese Produkte liefern.
Reis. 2.4. Infologisches Modell der Datenbank "Lebensmittel"
[ Zurück ] [ Inhalt ] [ Weiter ]
Datenbanken: Entitätsklassifizierung |
|
| Seiten in diesem Abschnitt | |